
MIEDO A LA I.A.
¿NOS DEBERÍA PREOCUPAR LA IA?
¿Puede un robot tener sentimientos? ¿Puede un robot ser creativo? ¿Puede un robot amar? Todas estas preguntas, que podrían parecer absurdas si las pronunciamos en alto, están siendo debatidas en el momento actual por científicos prestigiosos en los más elevados foros internacionales. ¿Qué está ocurriendo? ¿Realmente nos estamos planteando que las máquinas lleguen a tener peculiaridades hasta ahora solo atribuibles a los humanos? Partimos de un hecho claro. La revolución tecnológica que estamos viviendo en la actualidad no permite cerrar ninguna posibilidad por inverosímil que nos pueda parecer.
Robots humanoides, sistemas de Inteligencia Artificial (en adelante, IA), máquinas pensantes... todos estos términos se entremezclan en la imaginación de la sociedad y, junto con informaciones a veces confusas e incompletas, pero sin duda impactantes y cuanto menos curiosas, contribuyen a crear cierta alarma social en algunos casos; en otros, expectación desmesurada por saber cómo será nuestro cinematográfico futuro. Y no es para menos. Ninguna otra tecnología precedente había hecho plantearnos preguntas similares. Para entender el porqué debemos trasladarnos, por un lado, a la ciencia ficción. La imaginería popular ha adquirido ciertos prejuicios asociados a la cinematografía y las novelas de este género. Principalmente en el mundo occidental, películas como 2001 , odisea en el espacio (1968) o Terminator (1984) plantean un escenario apocalíptico en el que “máquinas” autónomas toman sus propias decisiones y suponen un perjuicio para el ser humano.
Ahora algunos de estos “robots” han saltado de la gran pantalla a los telediarios. Lo que, hasta hace unos años, era ciencia ficción ahora es realidad. Todo esto, a la sociedad en general, le hace plantearse si los siguientes pasos que nos esperan no serán similares a los que veíamos en estas apocalípticas películas. Por otro lado, tenemos el hecho de que los sistemas de IA tienen una capacidad que, hasta ahora, solo era inherente al ser humano: la toma de decisiones. En este sentido, no es tan descabellada la incertidumbre que se genera al pensar que si, tras la Revolución Industrial, las máquinas asumieron muchas tareas físicas, si ahora asumen también las intelectuales... ¿qué nos quedará a nosotros, los humanos?
GRANDES INVERSIONES MAYOR EFICIENCIA... Y ¿PELIGRO REAL?
La Inteligencia Artificial (IA) existe desde los años 50 del siglo pasado; sin embargo, a partir de 2010, empezó a experimentar un rápido crecimiento motivado por la explosión del llamado Big Data: la capacidad de almacenaje de los datos, el aumento de la potencia de computación y por nuevas técnicas, como el aprendizaje profundo. Las predicciones apuntan que, en los próximos años, el desarrollo de la IA será exponencial en gran parte motivado por las enormes inversiones, tanto privada como pública, de la que disfruta esta tecnología en todo el mundo, y por las expectativas de rentabilidad y la capacidad transformadora que se atribuya a esta tecnología.
Actualmente, se están invirtiendo miles de millones de dólares en el desarrollo de esta tecnología. La evolución del machine learning (aprendizaje automático), el deep learning (aprendizaje profundo), el procesamiento de lenguaje natural (capacidad de las máquinas para procesar el lenguaje natural) y la robótica marcarán el futuro más inmediato de la Inteligencia Artificial. Y estas cuestiones supondrán una revolución en cuanto a la forma en la que asumiremos esta tecnología en nuestro día a día, también en la forma en la que nos relacionaremos con las “máquinas”.
Ya en la actualidad hay una tendencia clara a los dispositivos conectados: “Internet de las cosas”, smart cities... Todo este Big Data que se genera requiere de IA para gestionarse de manera eficiente. En breve, tendremos tecnologías de IA en muchos dispositivos que usamos de manera habitual. Todo esto generará productos y servicios más personalizados que los que tenemos ahora. Para todas las empresas, no solo las grandes, supondrá un ahorro importante de costes, una vez resuelta la inversión inicial, ya que podrán basar sus desarrollos según predicciones y patrones muy concretos con un alto porcentaje de fiabilidad. Además, veremos el surgimiento y la rápida evolución de la medicina predictiva, de tratamientos médicos personalizados, de sentencias judiciales más rápidas... Habrá una mayor eficiencia en todos los procesos que empleen IA.
Sin embargo, esta rápida aceleración, unida a las motivaciones económicas, hacen tambalearse los cimientos del razonamiento lógico y, sobre todo, responsable que daría lugar a una tecnología fiable y realmente beneficiosa para la humanidad. El peligro, aunque dependa de nosotros, o quizá justo por ello, ¿es real?
Son muchos los renombrados científicos que advierten del peligro real de la IA. En nuestro pensamiento, fluyen imágenes combinadas de robots imaginarios que demandan igualdad de derechos, como en "El hombre bicentenario", 1999, junto con noticias de uso de IA para el desarrollo de armas autónomas. ¿Máquinas tomando decisiones importantes? ¿Incluso con derechos? La gran pregunta es: ¿y por qué no va a ser posible? ¿Llegará un día en que confiaremos tanto en las máquinas que delegaremos en ellas cualquier ámbito de nuestra rutina diaria? Si lo pensamos así, en frío, desde luego para muchos supondrá, al menos, cierta incertidumbre. Sin embargo, aunque a un nivel mucho menor, casi imperceptible para que seamos realmente conscientes de ello, el primer paso hacia esta realidad ya lo estamos dando.
Quién no se ha dejado llevar por el GPS, con una confianza tan ciega que ha acabado por el “camino de cabras” más recto hasta su destino, a pesar de que la señalización física indicara algo diferente. Si lo dice Google Maps, estará bien. ¡Seguro! Esto es algo incuestionable. Pensemos ahora en nuestras soñadas vacaciones, en nuestro coche ideal o en el mejor seguro para nuestro hogar. Hace ya unos cuantos años para asesorarnos debíamos recurrir físicamente a expertos en el sector: ir a una agencia de viajes (o a varias), y lo mismo con los concesionarios de coches. El proceso podría llegar a tardar incluso meses. Probablemente, cuando lo considerábamos terminado, habíamos olvidado lo que nos dijeron en la primera consulta. Pero era nuestra rutina. La asumíamos y nos conformábamos.
Sin apenas darnos cuenta, hemos ido confiando, cada vez un poco más, en las recomendaciones de las máquinas. En principio los datos “no mienten”. Al menos, nosotros no somos conscientes de que lo hagan. Si preguntamos a un buscador cuál es el mejor colegio en nuestra zona, nuestra decisión final suele ser un colegio que estaba en este listado del buscador. En esto aún somos usuarios activos. Tenemos que marcar “a mano” nuestras preferencias. Pero ¿qué hay de la confianza inconsciente en las máquinas? Cada vez son más los servicios que usan sistemas de recomendación para afianzar clientes. Todos tenemos nuestras preferencias, incluso, sin saberlo en muchas ocasiones, nos dejamos llevar por ellas. Es el caso de la plataforma de series, películas y documentales Netflix, por ejemplo. Su gran éxito radica en el sistema de recomendaciones basado en varios tipos de datos de sus clientes. Netflix procesa todos estos datos y realiza predicciones para sugerir las siguientes películas o series. Algo similar sucede con Amazon y las compras. ¡A veces incluso parece que Amazon sabe lo que quieres comprar antes que tú mismo! Hay días en los que te dejas llevar. Es cómodo y las recomendaciones se ajustan a tu perfil. ¿Por qué no lo vas a hacer?
Este paso que acabamos de citar todavía es asumible. Son procesos más o menos simples que, normalmente, no nos hacen pensar mucho, en el caso de que nos vuelva la “consciencia”, sobre la influencia de la máquina en nuestra decisión. Pero con los desarrollos actuales en Inteligencia Artificial el tema se complica. El sistema no solo es capaz de recomendar, sino también de ejecutar. No mucha gente sabe que el 75 % de todas las transacciones de compraventa de acciones en las bolsas se ejecutan de manera automática por algoritmos. Otro ejemplo aún más claro y, al menos aparentemente, más preocupante es la toma de decisiones autónomas por las llamadas LAWS, por sus siglas en inglés (Lethal Autonomous Weapon Systems). La película "Espías desde el cielo" (Eye in the Sky , 2018) muestra muy bien el posible conflicto. Aquí se usan drones teledirigidos, a decenas de miles de kilómetros, para matar a terroristas. Las bajas militares se reducen, sin duda. Y la precisión aumenta. Sin embargo, aquí entra en juego el contexto. Algo que aún la máquina no entiende. En la película, la decisión final sigue en manos de los humanos, por mucho que la ejecute o no un dron. La ética y la valoración del contexto le sigue correspondiendo a las personas, aunque no sean decisiones fáciles, ya que puede haber información incompleta y daños colaterales. En cualquier caso, la cinta suscitó cierta controversia e intranquilidad. ¿Qué pasaría si el dron hubiera sido autónomo al 100 % y hubiera actuado solo basado en los datos y en los niveles de probabilidad y, en definitiva, lo que según esos datos y el algoritmo fuera lo mejor para la obtención del resultado esperado?
La pregunta y la alarma que despierta su interpretación son perfectamente normales, más partiendo del hecho de que también los algoritmos cometen errores. Y jamás deberían equivocarse, en una decisión autónoma, cuando está en juego una vida humana. La gran pregunta es: ¿cómo podría una máquina decidir si los “daños colaterales” están justificados? Esto es algo que, incluso para las personas, supone una gran dificultad. A este concepto se le conoce como human-in-the-loop (HITL): los humanos seguimos y seguiremos teniendo la última palabra sobre decisiones que afectan a la vida o a la muerte.
Stop killer robots
Son muchos los países que en la actualidad se han mostrado contrarios a permitir ciertos grados de autonomía en cuanto al desarrollo de armas letales. El marco regulatorio a este respecto es una prioridad y los criterios que se deberían aplicar parecen muy claros, todos basados en que una máquina nunca puede llegar a tener la última decisión sobre la vida y la muerte. Pero el hecho es que la industria armamentística mueve más de un billón y medio de dólares a nivel mundial. Es un negocio muy rentable y la IA supone una revolución tecnológica de extremo interés para este sector. Es difícil parar este desarrollo. Sin embargo, los intentos no han parado.
En verano de 2015, científicos y expertos en IA, entre los que se encontraban el astrofísico británico Stephen Hawking, el emprendedor Elon Musk, presidente de Tesla y SpaceX, y Steve Wozniak, cofundador de Apple, firmaron un manifiesto en contra de las armas autónomas. La IA, implantada en estas máquinas, no solo podría suponer un incentivo de riesgo y daño al enemigo en los conflictos bélicos al no ver expuestas directamente sus tropas humanas, sino que también dejaríamos de controlar determinadas circunstancias coyunturales difíciles de captar en datos y, por lo tanto, al menos por ahora, imposibles de considerar por parte de las máquinas.
Sesgos en los algoritmos
Hay veces que los riesgos de la IA son obvios. Sin embargo, hay otras en que no lo son tanto y, hasta que no se aplican y se ruedan, no vislumbramos las consecuencias. Es algo que está siendo muy recurrente en este tipo de tecnologías que nos abruman y nos ciegan con sus inmensas y aparentemente muy ventajosas posibilidades, pero que, incluso sin querer, esconden cierto lado oscuro. Este es el caso que acaeció a Brisha Borden. No es el único caso, pero sí fue muy concluyente para empezar a aprender los posibles sesgos de las máquinas en base a los datos con los que son entrenados.

Algo similar ocurrió con el gigante tecnológico Amazon. En 2014, desarrolló un algoritmo para agilizar la contratación de empleados. Esta herramienta analizaba las solicitudes presentadas en la última década e identificaba patrones. No se dieron cuenta en el proceso de recopilación de datos que, durante esta época, la gran mayoría de los aspirantes habían sido varones y por eso también la mayoría de los bien cualificados. Así que la IA, tras su entrenamiento, empezó adiscriminar los currículos de mujeres frente a los de los hombres. Al cabo de un tiempo, Amazon se dio cuenta y retiró el algoritmo. Una vez más resulta que la IA, en un momento de la historia en la que aún estamos aprendiendo su potencial y sus posibles riesgos, no carece de polémica.
Un caso más. En noviembre de 2019, la discriminación sexista saltó a otro gigante de la tecnología, Apple, tras descubrirse que su tarjeta bancaria Apple Card estaba dando ventajas en el crédito a los hombres frente a sus esposas, estando ambos en las mismas condiciones financieras. El emprendedor tecnológico David Heinemer Hansson comentó cómo su límite de crédito era veinte veces mayor que el de su esposa. Además, esta no tenía la posibilidad de recuperar la capacidad de crédito antes del vencimiento mensual, pagando la cantidad debida. Apple respondió a las críticas argumentando que su compañía no tiene, ni ha tenido en ningún momento de su historia, comportamientos sexistas y todo lo achacó al “inexplicable algoritmo”.
Automóviles con valores éticos
Volviendo al tema de máquinas autónomas, estas últimas preguntas también están tratando de responderse en otro de los grandes focos actuales de la Inteligencia Artificial: la conducción autónoma. ¿Sería responsable dejar a un coche conducir “sin supervisión” humana? Técnicamente es posible, pero ¿debemos? Ya han sido varios los casos de atropellos mortales por parte de coches que conducían “solos”. A veces, ha sido porque el peatón no estaba cruzando de forma conveniente por el paso de cebra y el algoritmo no había sido entrenado con datos que reflejaran estas situaciones. Otras, por un fallo en lo sensores debido a condiciones climatológicas. El hecho es que la conducción puede estar influida por una serie de factores contextuales difíciles de prever y, por tanto, difíciles de incluir en los datos de entrenamiento del algoritmo. Por tanto, al menos por ahora, esta supervisión humana sigue siendo altamente recomendable.
También debemos de tener en cuenta que, en la actualidad, la mayoría de los accidentes de tráfico que ocurren son debidos a despistes o actos de irresponsabilidad humanos, por lo que tampoco es descartable que, en un futuro próximo, una IA más desarrollada en valores y circunstancias contextuales nos ayude a mejorar los índices de accidentes en las carreteras, así como a fomentar la organización del tráfico en las ciudades y reducir los niveles de contaminación.
Como vemos, ya hay muchos casos que han despertado la alarma social debido a un error de un algoritmo, ya haya sido intencionado o no. Analizaré a continuación cuál es la base tecnológica, es decir, cómo funcionan los algoritmos de IA en cuanto a la posibilidad de sesgos o “errores” en los datos. De esta manera, se ayudará a comprender el riesgo real y aquello que, al menos en estos momentos, sigue perteneciendo a la ciencia ficción.
LA INCONSCIENCIA DEL SER HUMANO
¿Qué significa mentir? ¿Quizá simplemente no decir la verdad? Según una de las acepciones que podemos encontrar en el diccionario de la Real Academia Española (RAE), sería: “Decir o manifestar lo contrario de lo que se sabe, cree o piensa”. Por lo tanto, si nos atenemos a esta, sería una acción consciente. El ser humano sabe que “no es cierto” cuando ejerce esta acción, al menos normalmente. Los algoritmos, por el momento, no tienen consciencia del por qué realizan sus acciones. Por lo tanto, la máquina no miente. Traslademos, pues, el problema de nuevo al “humano”, que es el único que, por ahora, tiene esta peculiaridad que tratamos de exportar tan fácilmente. ¿De qué manera pueden afectar las decisiones humanas, ya sean conscientes o inconscientes, a la IA? Comenzaré explicando qué es un algoritmo de IA y el modo en el que trabajan.
Sistemas “inteligentes” de aprendizaje automático
Simplificando, un sistema de IA es un software, programa informático, que procesa datos y genera decisiones en base a los datos analizados. La “fórmula” que más se está usando en la actualidad para su desarrollo es el llamado machine learning, aprendizaje automático. En este caso, al contrario del cerebro humano, la Inteligencia Artificial necesita grandes cantidades datos para realizar el análisis (el aprendizaje) que le lleva a sus conclusiones.
La IA, por ahora, se alimenta de las bases de datos que nosotros le proporcionamos. De hecho, uno de los grandes problemas que había tenido esta tecnología para desarrollarse, desde sus inicios, en los primeros años de la década de los 50, fue la falta de datos. La expansión de Internet y sus inherentes características soluciona este problema generando un Big Data (crecimiento exponencial de los datos), que, junto con el incremento en la potencia de los ordenadores y el aumento de la capacidad de almacenaje de los datos, salvó este escollo. Sin embargo, trajo consigo nuevas dificultades. Algunos de estos datos no son veraces, aunque no se tenga consciencia de ello. Otros pertenecen a situaciones muy específicas, ya sea temporales o culturales, y, sacados de contexto, pierden su razón de ser. Los datos, de por sí, no generan conocimiento, pero sí su análisis y procesamiento. Si un eslabón, en esta cadena de proceso, está alterado, acaba afectando a su totalidad. Este es el peligro que existe en la toma de decisiones por parte los algoritmos.
Pero ¿qué hace el algoritmo, o modelo, con los datos? Entrenarse, como lo haría cualquier persona con un claro objetivo, para llegar a tomar la mejor decisión posible. Cuanto más se entrene (de cuanto más datos disponga), mejor llegará a la meta (decisión). El modelo compara, analiza y extrae patrones. Así puede clasificar, discriminar y agrupar en distintas categorías útiles. Gracias a estos patrones, es capaz de “afrontar” situaciones nuevas. Las compara con las que ya “ha vivido” similares y extrapola. Así, también puede realizar predicciones, a través de cálculos de probabilidad, con un alto índice de acierto, siempre en función de su nivel de entrenamiento y de la fiabilidad de los datos con los que ha sido entrenado.
De manera general, podemos hablar de tres tipos principales de aprendizaje automático: supervisado, no supervisado y el llamado "reinforcement learning". Intentemos bucear, a través de un ejemplo, en cada uno de estos conceptos para quedarnos con la idea general necesaria para entender el proceso.
• Aprendizaje automático supervisado: Imaginemos que queremos entrenar un sistema de IA para reconocer gatos en fotos. En este caso, le enseñamos miles de fotos con gatos y otras que no los muestran. De esta manera, el sistema aprende qué características de las fotos corresponden a gatos y cuáles no. Así, ante una nueva foto, el sistema es capaz de decir si aparece un gato o no. Estos sistemas no siempre suelen acertar. Cometen errores que se conocen como “falsos positivos” al reconocer gatos donde no los hay, y “falsos negativos” al no reconocer un gato donde sí lo hay.
• Aprendizaje automático no supervisado: Pongamos, por ejemplo, que se presenta al sistema de IA la base de datos de clientes de una empresa. El algoritmo, por sí mismo, se encarga de agrupar los datos en grupos que maximizan las características comunes y minimizan las características distintas. De esta manera, se puede segmentar automáticamente una base de datos con muchos clientes en grupos interesantes.
• Reinforcement learning: El uso de algoritmos de IA para jugar al ajedrez o al juego del go es uno de los mejores ejemplos. En este caso, el sistema aprende por prueba y error. Recibe una recompensa o penalización por cada movimiento que propone según se acerca o se aleja del objetivo de ganar. Aprende a base de jugar muchas partidas para quedarse con los mejores movimientos.
Sistemas basados en conocimiento
Además del machine learning , hay otro tipo de sistemas de IA que no se basan en el aprendizaje según la “ingesta” masiva de datos, sino directamente en el conocimiento y en un “motor de inferencia”, que extrae un juicio o conclusión a partir de los hechos. La base de conocimiento contiene hechos y relaciones relevantes para el propósito final del algoritmo. Por ejemplo, si tenemos un sistema de IA que diagnostica automóviles, la base de conocimiento contiene información sobre los componentes de un coche: cómo están conectados, dónde se encuentran en el coche, cuál es la función de cada componente y cómo funcionan conjuntamente, cuáles son sus fallos más típicos, cuáles son las causas más frecuentes, etc.
En el caso de un sistema de IA médico, la base de conocimiento consiste en las partes del cuerpo, los órganos relevantes, a través de qué sistema biológico se relacionan y cómo, dónde se encuentran en el cuerpo, etc. Además de esta base de conocimiento que representa todos los hechos que pensamos que se deben de tener en cuenta, y las relaciones entre ellos, estos sistemas “razonan” a través del motor de inferencia con los hechos para dar como resultado nuevos hechos y conclusiones. Un ejemplo clásico de razonamiento lógico es:
"Todos los hombres son mortales. Sócrates es hombre, luego Sócrates es mortal"
Esta regla de inferencia deductiva se llama “silogismo” y fue formulado por primera vez por Aristóteles. Un silogismo consta de proposiciones distintas que actúan como premisas, y una tercera que es la conclusión del razonamiento lógico. En este sentido, los motores de inferencia se implementan, normalmente, por reglas del tipo “SI ‘condición’ Y ‘condición’ Y ... Entonces ‘conclusión’”, además de un mecanismo de encadenar las reglas hasta llegar a una conclusión.
Existen estrategias diferentes para encadenar estas reglas, como el “razonamiento hacia atrás” (empieza por la conclusión y aplica reglas hasta que solo quedan hechos) o el “razonamiento hacia delante” (se empieza por los hechos y ejecuta las reglas hasta haber llegado a una conclusión válida). Para decidir cómo encadenar las reglas, existen varias estrategias conocidas en el campo de la Inteligencia Artificial como “búsquedas” (depth first , breadth first, hill climbing, A-star, etc.). Tradicionalmente, las bases de conocimiento que acabo de comentar son creadas por los llamados “Ingenieros de conocimiento”, que extraen la información relevante de la literatura o lo adquieren mediante entrevistas con expertos. Estos algoritmos se suelen llamar “sistemas basados en conocimiento”, “sistemas expertos” o “sistemas basados en reglas”. La representación de la base de conocimiento también se llama “ontología”.
Todos estos forman parte de la escuela de la “IA simbólica”. Uno de los primeros sistemas de este tipo fue MYCIN, desarrollado para facilitar y acelerar el diagnóstico de enfermedades de la sangre, como la meningitis y la bacteriemia, y así ayudar a los médicos, ahorrándoles tiempo y esfuerzo. MYCIN era capaz de identificar las bacterias que causaban la infección en los pacientes. También podía sugerir los antibióticos y las dosis adecuadas para el peso de cada paciente. En el mundo empresarial, el ejemplo más conocido es el de la compañía Cycorp, cuya ambición es modelar el sentido común a través de bases de conocimiento y una multitud de motores de inferencia. Su fin es crear “máquinas” con sentido común capaces de razonar como los humanos.
La diferencia entre sistemas de IA basados en reglas y datos se explica en las dos figuras que se exponen a continuación. En un sistema de IA basado en reglas, cada algoritmo tiene una entrada y una salida: entran los datos (por ejemplo, síntomas), el algoritmo procesa esos datos según sus instrucciones y sale el resultado (una diagnosis). El algoritmo ha sido programado por personas (primera figura). Con sistemas de IA basados en datos (aprendizaje automático), es al revés: entran los datos y el resultado deseado, y el output es el algoritmo que ahora es capaz de convertir los nuevos datos de entrada en el resultado correspondiente (segunda figura).
En cierto modo, con aprendizaje automático, los ordenadores son capaces de “escribir” sus propios algoritmos
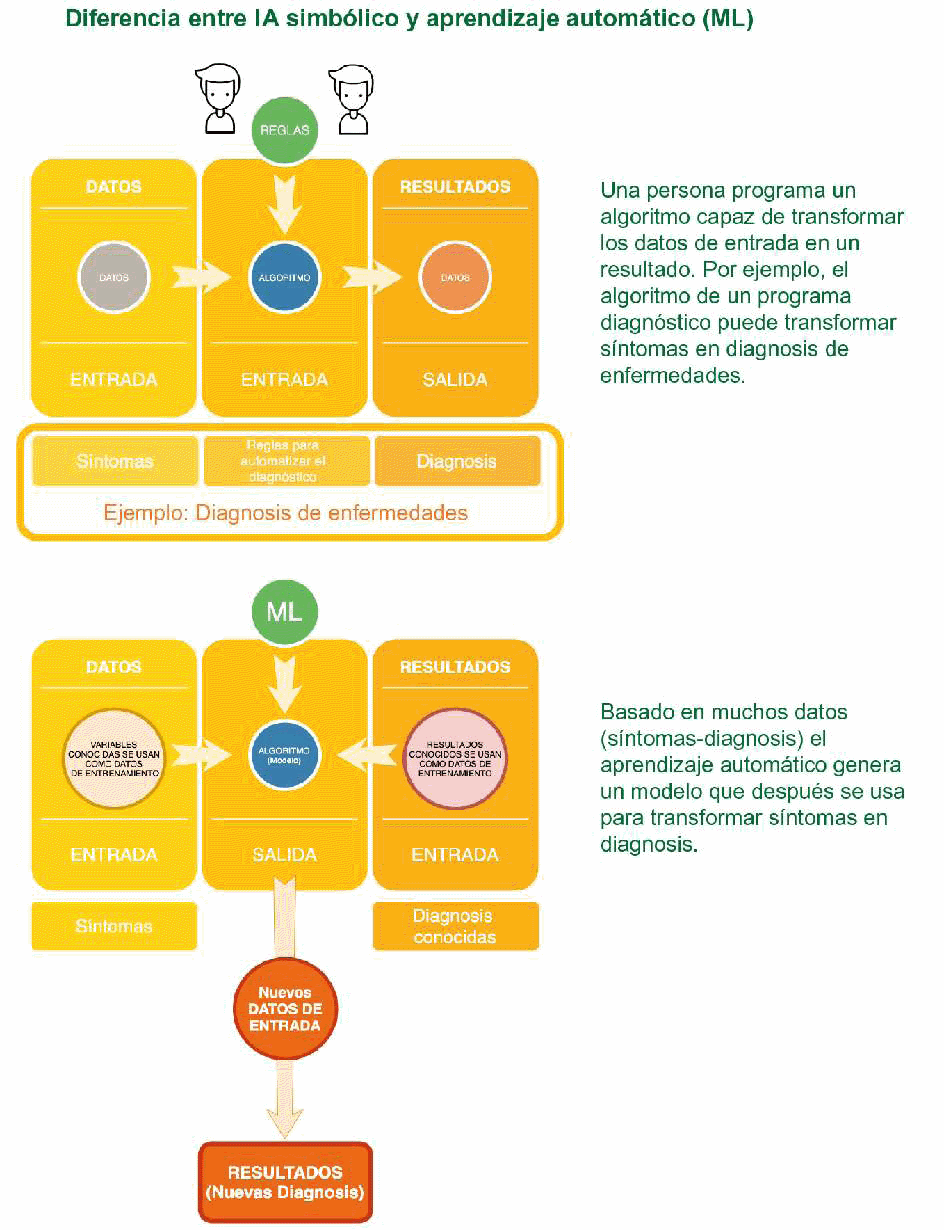
Una vez conocidos cuáles son los elementos que componen un algoritmo y, en cierta medida, también cómo desarrollan sus procesos, es el momento de intentar comprender cuáles son los riesgos reales que presentan, principalmente en el caso del machine learning, y también de intentar desmentir los prejuicios e ideas falsas o irreales asociadas a la toma de decisiones por parte de las máquinas.
DECISIONES JUSTAS Y BIEN EXPLICADAS
La Inteligencia Artificial está todavía en sus inicios. Aun así, ya hemos advertido ciertos riesgos derivados de la “excesiva confianza” en esta tecnología. Su capacidad nos lleva a delegar en ellas, a veces sin prever las posibles consecuencias sociales o profesionales negativas. Diversos casos, como el de Amazon o Apple, citados con anterioridad, son la prueba de estas consecuencias no deseadas, aunque no intencionadas. Pero también sabemos que las personas no siempre decimos la verdad ni somos siempre justos por nuestros prejuicios y nuestras experiencias pasadas.
La motivación del Big Data y los algoritmos fue justamente mitigar estos problemas de las personas hacia decisiones más objetivas, justas y basadas en la realidad. ¿Es verdad que las máquinas lo hacen mejor? ¿Y que no tienen prejuicios ni “mienten”? ¿Debemos tener miedo de que las máquinas nos vayan a controlar? ¿Y de que las máquinas vayan a tomar las decisiones importantes que deberían quedarse en manos de las personas? ¿Podremos siempre entender por qué una máquina toma una determinada decisión? ¿Vamos a poder controlar si las máquinas discriminan a las personas más vulnerables? ¿Qué hay de verdad en todo esto? ¿Cuáles son las cuentas y cuáles los cuentos? ¿Nos van a controlar las máquinas?
Hoy por hoy, es un cuento que las máquinas nos van a controlar. ¿Por qué? Estamos en la época de la IA estrecha o IA débil. Esto quiere decir que la IA puede resolver tareas concretas con situaciones predecibles, donde hay muchos datos disponibles para entrenar al algoritmo. Además, este tipo de IA no “sabe” qué está haciendo, no sabe qué es un gato en una foto ni que está reconociendo una cara en una aplicación de reconocimiento facial. Lo que aprende el algoritmo son aquellas características (por ejemplo, píxeles en fotos) que todos los gatos tienen en común, pero no sabe que está reconociendo un gato, cuál es su significado. De hecho, si todas las fotos de entrenamiento, aparte de un gato, también contienen un árbol, reconocerá gatos con árboles, pero no los gatos sin árboles.
En cualquier caso, los algoritmos de IA en la actualidad, (2020), que se basan en reconocimiento de patrones con aprendizaje supervisado, son suficientemente buenos para desarrollar tareas concretas y complejas que a los humanos nos sobrepasan o nos pueden suponer invertir demasiado tiempo. Sobre todo, destacan en su precisión, por ejemplo, en la selección de candidatos para un puesto de trabajo o en los diagnósticos a través del análisis de radiografías. Sin embargo no tienen conocimiento de lo que están haciendo. En el caso de gatos y enfermedades, solo ven píxeles; no saben de ojos, orejas ni de tumores o manchas oscuras, mucho menos de qué es un gato o una enfermedad grave. Incluso programas que combinan técnicas distintas de IA, como el deep learning, reinforcement learning y search, y las usan en distintas fases del problema, como AlphaGo de Deepmind, tampoco son “conscientes” de que están jugando al go. A pesar de “saber” mucho del juego más complicado del mundo, AlphaGo no es capaz de jugar a un juego estratégicamente más fácil, como puede ser el ajedrez o las damas. Ahí está, por ahora, una de las diferencias con los humanos. En principio, una persona capaz de jugar al go como maestro es capaz de jugar, bastante bien, una partida de ajedrez o damas.
El paso a un programa de IA capaz de desarrollar tareas múltiples, como lo haríamos los humanos, no es viable en la actualidad. Sin embargo, no se puede descartar que en un futuro lo sea. Esa capacidad es una condición necesaria, aunque no suficiente, para llegar al momento que se conoce como “singularidad tecnológica”. Supuestamente, será el punto de inflexión en el que las “máquinas independientes” nos sobrepasen en todos los aspectos de nuestra inteligencia y serán capaces de actuar y replicarse a sí mismas, desempeñar multitareas y, quizás, superarnos como raza. Si se consiguiera, sería la prueba de que, como hombres, somos capaces de crear “seres conscientes” de la nada, con capacidad para socializar y con una inteligencia superior. En cualquier caso, aún estamos muy lejos de la Inteligencia Artificial general, como tenemos los humanos. Hace falta tener sentido común, poder razonar y entender relaciones causales. Todo esto, hoy en día, son cosas de las que carece la Inteligencia Artificial. Si algún día llega a ocurrir tal idea apocalíptica (que abarcaré con amplitud en otro artículo), no tiene por qué ser negativa, siempre que, desde ahora, guiemos el desarrollo de esta tecnología con responsabilidad, manteniendo siempre al humano como centro de ella.
Nosotros, los humanos, somos los que debemos razonar sobre las decisiones que debemos dejar en manos de la máquina. Hoy en día, en la cultura occidental, son las empresas y organizaciones las que están decidiendo qué decisiones quieren automatizar o no; es el mercado libre el que decide. Pero, en un futuro próximo, quizá la decisión pase por un organismo regulador que controle y realice una prevención real sobre un posible impacto negativo de estas tecnologías. De todas formas, en China, el gobierno ya marca las decisiones sobre IA, cuestión que no debe sorprendernos demasiado.


Es importante intentar prever el tremendo potencial que podría llegar a tener esta tecnología en un futuro, pero lo es aún más comprender, en el momento actual, sus características intrínsecas y el posible conflicto con las de la raza humana, así como sus riesgos reales. Sigamos con algunas de estas características.
¿Son todas las decisiones de las máquinas cajas negras?
Hay veces que, incluso para los humanos, tomar decisiones no es fácil. Nuestro cerebro analiza y pondera cuál es la mejor opción. Cuando alguien te pregunta por qué has tomado esta decisión, normalmente, eres capaz de explicarlo. Razonarlo. Y también, normalmente, el interlocutor lo entiende. ¿Pero qué ocurre con las máquinas? ¿Podemos hacerles la misma pregunta para intentar entender su razonamiento?
Lo primero que hay que mencionar es que, actualmente, los algoritmos de IA dependen íntimamente de su programador inicial. Es esta persona la que decide qué algoritmos usar y con qué datos entrenar el modelo. Por lo tanto, en el tema de la “explicabilidad” de las conclusiones a que llegan los algoritmos, el primer responsible es el ingeniero. Los resultados de los algoritmos más potentes de la IA, los de deep learning , en efecto, son difíciles de entender, ya que el proceso que desarrolla es opaco. Se les conoce como Black Box, caja negra. Sin embargo, hay muchos algoritmos de aprendizaje automático que son perfectamente inteligibles (cajas blancas) para saber cómo ha llegado a una determinada conclusión. Por ejemplo, los llamados “árboles de decisión” son perfectamente comprensibles.
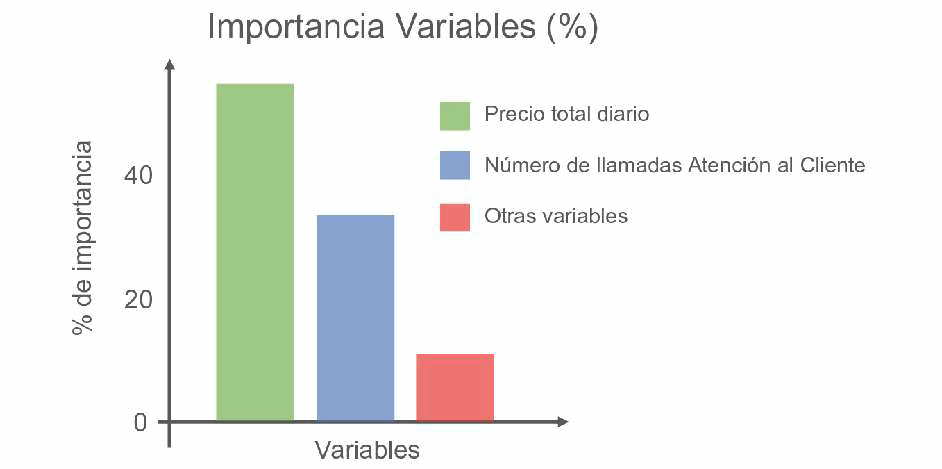
En las dos figuras que se exponen a continuación, se puede apreciar el resultado de un árbol de decisión para predecir si los clientes van a abandonar una compañía de telecomunicaciones o no, basado en datos históricos. El árbol es entendible por personas y el algoritmo puede demostrar todas las variables que han influido en su decisión y con qué importancia. Con los dos gráficos se puede entender cómo el algoritmo llega a una conclusión. Si un cliente paga mucho en un día (más de 40 dólares), entonces abandona la compañía. Si gasta menos de 40 dólares, pero ha llamado más de tres veces al centro de atención de cliente, también deja de ser cliente, pero, si ha llamado menos de tres veces al centro de atención, sí se queda con la compañía.

Árbol de decisión para predecir abandono de clientes
Además, se puede visualizar la importancia de cada variable en el proceso de decisión del árbol: precio total diario, número de llamadas al centro de atención al cliente, etc.
Aunque, hasta la fecha, la mayoría de los ingenieros prefieren usar deep learning (una caja negra) por sus prestaciones superiores, cada vez son más las empresas que consideran usar un algoritmo interpretable (caja blanca) si su prestación es suficientemente buena para resolver el problema de negocio, aunque sea su rendimiento un poco peor que un algoritmo de caja negra. La razón es la explicabilidad, que, en ciertas aplicaciones, debe tener un peso importante, como en el sector médico. De todas formas, hoy en día hay mucha investigación trabajando en mejorar la explicabilidad de los algoritmos de deep learning.
Con sistemas de IA basado en conocimiento, la explicabilidad no es un problema, ya que estos sistemas usan conocimiento explícito y reglas para llegar a sus conclusiones. Y, visualizando la cadena de reglas que ha usado, se supera la oscuridad que rodea a este proceso de razonamiento de la máquina. Por ejemplo, el sistema médico experto MYCIN era capaz de diagnosticar meningitis a través de una base de datos con conocimiento médico y un motor de inferencia. Y también podía explicar preguntas como: ¿por qué se ha usado esta observación en la diagnosis?, ¿por qué no se ha usado esta observación en la diagnosis?, ¿cómo llegó el sistema a su conclusión?, ¿por qué no llegó a una conclusión distinta? Sin embargo, si para llegar a una conclusión el algoritmo ha usado una cadena de más de mil reglas, tampoco es muy comprensible para las personas, ya que nos perderíamos en tanto detalle.
En cualquier caso, la explicabilidad en los algoritmos sigue siendo un reto. Para decisiones que impactan en nuestras vidas, es realmente necesario saber de qué forma han llegado a tomar sus decisiones. Solo así podremos adquirir confianza en ellos y sacar así toda su utilidad. Imaginemos un juez que se ayuda de un sistema de IA para el análisis de la jurisprudencia sobre un caso. La “decisión” del algoritmo no tendría validez si el juez no fuera capaz de explicar el porqué de este proceso. Sin embargo, este no es, ni mucho menos, el único reto de la IA. Mucho más claros son aquellos que intentan combatir los posibles sesgos que llevan a la discriminación en la toma de decisiones.
¿Conseguiremos controlar la discriminación de la IA?
¿Qué hay de ciencia, ficción y opinión en el miedo a los sesgos y a la discriminación? Comenzaré precisando el término “discriminación”. Para la mayoría de nosotros se asocia directamente con marginación relativo a la raza, sexo, política... Sin embargo, los algoritmos “discriminan” por diseño. Es su función discriminar entre clases de objetos. Por ejemplo, radiografías que presentan cáncer frente a las que no lo presentan; clientes que se van versus clientes que se quedan. Y aquí está el peligro. Se debe evitar el uso de variables sensibles, protegidas por la ley y los derechos humanos, que pueden conllevar problemas graves si se llegan a aplicar en una sociedad democrática.
Es un hecho que, en muchas ocasiones, la vida no es justa y que muchos de los datos que se generan reflejan este mundo injusto. Si un algoritmo aprende de estos datos sesgados, la decisión que recomienda puede estar sesgada de la misma manera, pero automatizada, lo cual es aún peor. Por ejemplo, si usamos datos estadísticos de los sueldos medios de hombres y mujeres para entrenar un algoritmo que ayuda a un departamento de RR. HH. a la hora de dar recomendaciones sobre salarios a nuevos empleados, seguramente el sistema discriminaría contra mujeres, ya que, estadísticamente, las mujeres tienen un sueldo inferior a hombres en puestos iguales.
Sin embargo, es ficción que necesariamente todos los algoritmos discriminen. Ya existen herramientas para mitigar los sesgos en los datos o en los algoritmos, para que el resultado del algoritmo no discrimine. Estas herramientas funcionan si el dato o atributo sensible (como género, raza o convicción religiosa) forma parte del data set, base de datos, de la que se alimenta un algoritmo. Se entrena el algoritmo sin estos datos sensibles y, después, se usan para verificar que el algoritmo efectivamente no discrimina contra este variable. No obstante, hay otros casos en los que los datos sensibles no forman parte del data set, entonces estas herramientas no son capaces de detectar si el algoritmo discrimina o no. Hay un caso más para tener en cuenta: las variables proxy son variables que, en sí mismas, no son sensibles, pero que tienen una alta correlación con datos sensibles.
Pensamos por ejemplo en la variable “código postal”. En algunas ciudades, el barrio donde vives, reflejado en un código postal, tiene una alta correlación con la raza de sus habitantes. De esta manera, si un algoritmo toma una decisión en base a esta variable, de forma indirecta podría discriminar a personas de raza negra. Algo asípodría haber pasado con el caso de la Apple Card, que, como hemos visto antes, discriminaba contra mujeres, ofreciéndoles mucho menos crédito que a las parejas de las mismas mujeres. Apple dijo que no discriminaba, ya que el género no formaba parte de las variables usadas para calcular el riesgo. No obstante, puede haber existido una variable proxy (con alta correlación con género) influyente en el modelo que ha causado esta discriminación.
Para comprender bien los riesgos reales, veamos, algo más en profundidad, cuáles son los tipos de sesgos identificados más comunes, teniendo en cuenta que, muy probablemente, haya otros muchos que aún lo hayan sido.
Sesgos en los datos
Hay veces que el sesgo se produce en la muestra, es decir, en los datos de los que se “alimenta” el sistema de IA, por ejemplo, cuando los datos recopilados no representan con precisión el entorno contextual en el que se espera que se ejecute el programa. Teniendo en cuenta el hecho de que no se puede entrenar a un algoritmo con todo el universo de los datos, es importante que el desarrollador preste mucha atención al subconjunto que elige en función de este contexto.
El sesgo más comentado en la prensa es cuando los datos usados para entrenar al algoritmo no son representativos para la población a la que se aplica el algoritmo. Si hacemos una foto con nuestro móvil, se suele ver un cuadro pequeño alrededor de cada cara: tiene un algoritmo por debajo que ha sido entrenado con muchísimas fotos de caras para distinguir las caras de las “no caras”. En las primeras versiones, el programa funcionaba bien para caras de personas de raza blanca, pero no para las de personas de raza negras. La consecuencia (lógica) era que solo se ponía un cuadrado alrededor de caras blancas, discriminando a las personas de raza negra. El error aquí es que los datos elegidos para el entrenamiento no eran representativos para el público objetivo. Este es el mismo tipo de sesgo que ocurrió con el sistema de IA de Amazon para la ayuda a la contratación que discriminó a mujeres.
Otros son los llamados “sesgo de exclusión”, que se producen cuando se eliminan algunas características pensando que son irrelevantes, basándonos en creencias preexistentes. Si se desconoce algún elemento que pudiera ser relevante en el contexto de los datos principales y se eliminan (inconscientemente), la muestra quedará sesgada. También se podrían producir sesgos en la medición y recogida de los datos en función del instrumento con el que se recojan. Es el caso, por ejemplo, de las imágenes sacadas con una cámara de fotos que tienen alterada la luminosidad o algún otro tipo de característica que distorsiona la realidad.
Sesgos humanos
Hay otros tipos de sesgos, más habituales aun que los contextuales en la actualidad, que son los pertenecientes a la persona que desarrolla el algoritmo o crea el modelo. Todas las personas influyen en sus creaciones, de una manera u otra. Es difícil dejar de hacerlo. En realidad, no tiene por qué ser malo, siempre que no tenga consecuencias negativas sobre la decisión. Este es el caso de los sesgos debido a los “prejuicios personales” del desarrollador, que acaban trasladándose al programa. Incluso puede ser un posible “auditor de datos” el que se vea afectado por su contexto personal, de una manera inconsciente, a medida que realiza su análisis y pasen desapercibidas algunas cuestiones importantes. Un ejemplo paradigmático lo tenemos aquí, en España, donde el CIS de Tezanos falsea sistemáticamente las encuestas sobre los resultados de las elecciones, con el objetivo de no morder la mano de quien le da de comer.
Pero, sin duda, de todos los sesgos citados, hay unos que suelen pasar más desapercibidos que los demás por una simple razón: es difícil darse cuenta de que algo influye, o no, en nuestra manera de ser y en el modo en el que tomamos nuestras decisiones, cuando convivimos a diario con ello en nuestro país, en nuestra cultura...
© 2020 JAVIER DE LUCAS