INDICE
1. Introducción a las redes de datos
1.1 Introducción
1.2 Redes para las
compañias
1.3 Redes para las personas
1.4 Aspectos sociales
1.5 El peligro de la
transculturización
2. Tipos de redes por su dispersión
2.1 Redes de Area Local
2.2 Redes de Area Metropolitana
2.3 Redes de Area Amplia
2.4 Red Global Internet
e internets
3. Protocolos de
Comunicación
3.1 Jerarquías
de protocolos
3.2 Aspectos de diseño
3.3 Interfases y servicios
3.4 Relaciones entre
servicios y protocolos
4. El modelo de referencia
OSI
4.1 Capas del modelo
de referencia
4.2 Transmisión
de datos en el modelo OSI
5. El modelo de referencia
TCP/IP
5.1 Las capas del modelo
TCP/IP
5.2 Comparación
con el modelo OSI
5.3 Programación
en red usando sockets bajo UNIX.
6. Ejemplos de redes
6.1 Vistazo a Novell
Netware
6.2 Vistazo a ARPANET
6.3 Vistazo a NFSNET
6.4 Vistazo a Internet
7. Ejemplos de servicios
7.1 SMDS
7.2 X.25
7.3 Frame Relay
7.4 ATM
8. Los niveles del modelo
OSI
8.1 Fórmula de
Nyquist
8.2 Medios de transmisión
nivel físico
8.2.1 Par trenzado
(UTP)
8.2.2 Cable coaxial
8.2.3 Fibra óptica
8.3 Transmisión
inalámbrica nivel físico
8.3.1 Transmisión
por radio
8.3.2 Transmisión
por microondas
8.3.4 Transmisión
infraroja
8.4 Transmisión vía satélite nivel físico
8.5 Aspectos del nivel
de ligado de datos
8.5.1 Detección
y corrección de errores
8.5.2 Protocolos del
nivel de datos
8.5.3 Estándares
para LANS y MANS
8.5.4 Dispositivos
físicos
8.6 Aspectos del nivel
de red
8.6.1 Servicios
8.6.2 Circuitos virtuales
y subredes
8.6.3 Ruteo
8.6.4 Congestionamiento
de la red
8.6.5 Firewalls
8.6.6 ATM
8.6.7 El protocolo
IP
8.6.8 Algunas notas
acerca de IP Versión 6
8.7 Aspectos del nivel
de transporte
8.7.1 Servicios
8.7.2 Direccionamiento
8.7.3 Protocolo TCP
8.7.4 Protocolo UDP
8.8 Aspectos del nivel
de aplicación
8.8.1 Seguridad de
la red
8.8.2 Repaso al DNS
8.8.3 Repaso al SNMP
1. INTRODUCCION A LAS REDES DE DATOS
1.1 Introducción
El desarrollo del hombre desde el nivel físico de su evolución, pasando por su crecimiento en en las áreas sociales y científicas hasta llegar a la era moderna se ha visto apoyado por herramientas que extendieron su funcionalidad y poder como ser viviente.
Durante la época prehistórica, el hombre se valió de la piedra, la madera y el metal para construir extensiones de su cuerpo: Un martillo o punta de lanza de piedra, obsidiana, madera endurecida al fuego para tener un alcance mayor de sus brazos y dominar a las bestias para conseguir el sustento diario. Después domesticó a los animales y construyó artefactos cada vez más complejos: Un arco para enviar sus "brazos" (flechas) en la distancia y subyugar a animales más peligrosos. Y así como extendió sus brazos, pronto encontró la forma de extender sus piernas para alcanzar lugares más lejanos: fabricó navíos para cruzar ríos, lagos y mares; carretas que los llevaban a lugares distantes más rapido que sus pies y con cargas mayores y hasta refinó las artes que le permitieron tener en el hogar paisajes y monumentos de la naturaleza para darse la sensación de tenerlos a su alcance en todo momento.
Finalmente, y sintiéndose conciente de su habilidad creativa, metódicamente elaboró procedimientos para organizar su conocimiento, sus recursos y manipular su entorno para su comodidad, impulsando las ciencias y mejorando su nivel de vida a costa de sacrificar el desarrollo natural de su ambiente, produciendo así todos los adelantos a los que un gran sector de la población conocemos: automóviles, aeroplanos, trasatlánticos, teléfonos, computadoras, televisiones, etc.
1.1.1 El cómputo electrónico
En el transcurso de todo este desarrollo, lo que nos interesa revisar es la evolución de un sector tecnológico: El cómputo electrónico. Este nació con las primeras computadoras en la década de los 40's con los tubos al vacío y los tableros de control enchufables. Y fue así porque la necesidad del momento era extender la rapidez del cerebro humano para realizar de algunos cálculos aritméticos y procedimientos repetitivos.
1.1.2 Las generaciones de computadoras
El esfuerzo en el cómputo electrónico se reflejó en crear unidades de procesamiento cada vez más veloces conforme la tecnología en la electrónica avanzaba. Así tenemos cuatro generaciones bien definidas: la primera con tubos al vacío, la segunda con transistores, la tercera con circuitos integrados y la cuarta con circuitos integrados que permitieron el uso de computadoras personales y el desarrollo de las redes de datos.
1.1.3 Las redes de datos
Una vez resuelto el problema de extender el poder de cálculo del cerebro humano nació o se comenzó a atacar el problema de compartir los datos y la información que ese poder de cálculo produjo, lo cual nos llevó a inventar la forma de compartir recursos (impresoras, graficadores, archivos, etc) a través de algún medio de transmisión usando una serie de reglas (proocolos) para accesar y manipular dichos recursos.
1.1.4 Los sistemas distribuidos
Las redes de computadoras nos permitieron reunir esfuerzos aislados
en esfuerzos conjuntos que producían bienes mayores (sinergia).
Sin embargo, en una red la forma de accesar dichos recursos va de la mano
con conocer la manera de llegar a esos recursos y saber cómo manipularlos,
es decir, no hay transperencia. El siguiente salto tecnológico-filosófico
es extender las redes de cómputo (extensiones del poder de cómputo
de cerebros humanos aislados) hacia los sistemas distribuidos (una entidad
vista como un todo y conformado por múltiples cerebros ubicados
en localidades alejadas unas de otras que nos ofrecen servicios y recursos
sin importar su ubicación).
Y si Carl Jung está en lo correcto respecto a su teoría
del conciente colectivo, parece ser que los adelantos tecnológicos
se van agrupando y homogeneizando hacia un conciente colectivo tecnológico.
Más información acerca de sistemas distribuidos vea [COL94]
1.2 Redes para las compañías
Cuando una persona física o moral establece una empresa siempre piensa en obtener beneficios y para esto, en muchas ocasiones se requiere de compartir recursos (impresoras, digitalizadores, computadoras, discos duros, archivos, el conocimeinto de personas, etc.) y una solución es tener una red que puede ser local, metropolitana, nacional, amplia o global, dependiendo su amplitud de la dispersión geográfica de los recursos que queremos compartir. Esos recursos deben están disponibles en el momento adecuado y que los datos o información que produzcan sean altamente confiables, esto es, que no sufran deterioro durante su transmisión. En ocasiones, será vital que contemos con réplicas de algunos recursos para que, dado el caso de un desastre en algún púnto de la red, podamos consultar o accesar un recurso similar o de respaldo.
Las compañías también se han dado cuenta que resulta
más barato tener una red de computadoras en donde reparten sus procesos
productivos que tener una sola supercomputadora en donde concentren todo.
Las ventajas de la red son: economía, capacidad de crecimiento más
granular, capacidad de soportar fallas, capacidad de tener réplicas
más económicas y otras.
1.3 Redes para las personas
El desarrollo tecnológico ha permitido que las computadoras sean accesibles cada vez a mayor número de personas en sus oficinas y en sus hogares, lo cual tambiém implica que se puedan crear micronegocios de alta competitividad y con gastos mínimos. Este tipo de negocios ya no tienen el problema de contar con enormes capitales, ahora su problema es el saber en dónde accesar los recursos que necesitan para proveer bienes y servicios.
Por otro lado, cada vez es más común el usar diveros servicios (correo electrónico, fax, operaciones de compra-venta, reservaciones en hoteles y líneas aéreas, pláticas interactivas persona a persona, acceso al diario en formato electrónico, WWW y videoconferencia) desde una computadora personal en el hogar.
1.4 Aspectos sociales
Desde el momento en que un monitor en casa permite el acceso a tan variados recursos, se corre el riesgo de ver cosas indeseables. Existen en Internet diversos bancos de información accesibles desde Foros de Información (newsgroups), Boletines de Información (Bulletin Board Systems), Páginas de Web, etc.
Muchos de los bancos de datos requieren de algún tipo de permiso (proveer un nombre de usuario y clave de acceso) para accesarlos. Otros permiten el acceso abierto y aquí reside el problema principal. Podemos darnos cuenta de temas que algunos sectores de la población apoyan y que van contra nuestros principios (por ejemplo el tema del aborto, la pornografía, el racismo, etc.) y en algunos casos junto a los datos podemos ver imágenes que ofenden nuestro gusto o que pueden ser traumáticas para nuestros hijos. Y entonces enfrentamos el problema de que este vasto terreno de información puede estar fuera de control y accesible, tal vez, a personas no aptas o no preparadas para digerirlo. Este problema es similar a controlar las emisiones de las cadenas televisivas donde se sopesan la libertad de expresión contra los principios éticos y morales.
1.5 El peligro de la transculturización
En la época moderna estamos viviendo bajo el paradigma de las modas. Se nos ha estado presionando para que tengamos en el hogar los aparatos electrónicos de moda (videos, televisores, decodificadores de cable, computadoras, teléfonos, fax, alarmas), aparatos de transporte de moda (automóvil, avión, yate, etc.), aparatos personales de moda (rasuradora eléctrica, agenda, calculadora, despertador, teléfono celular, etc.), diversiones de moda (videojuegos, viajes a lugares exóticos, centros nocturnos, clubes, conciertos, encuentros deportivos, etc) y así sucesivamente. La persona que cuenta con el mayor número de estos recursos y diversiones es la más destacada y digna de ser tomada en cuenta en conversaciones y homenajes, aunque no produzca ningún bien tangible para la sociedad. Todos estos acercamientos a las modas llevan el tiítulo lavacerebros de "progreso", "modernización", etc. y cambian totalmente la calidad de vida de las personas y la población en general.
Es tan fuerte el llamado a la "modernización", que las sociedades, al tener disponible el acceso a los medios electrónicos (por ejemplo Internet), rápidamente se van dando cuenta de costumbres y adelantos tecnológicos en todo el mundo y seguramente, si tienen o llegan a tener el recurso económico van a tratar de comprar esos adelantos. ¿ Qué país se resiste al progreso y al modernismo ? ¿ Hay otros caminos para vivir mejor ? ¿Existe alguna otra forma de vivir que no sea el de ser dueño o empleado de alguna empresa, ir a trabajar por la mañana, regresar en la noche, repetir eso todos los días y tal vez descansar los fines de semana? Ah! Y mantenerse a la moda. Una pregunta es: ¿Cuál será la correlación entre el porcentaje de cremiento al acceso a Internet y el nivel de transculturización?
Otra pregunta es: ¿ Será todo esto un camino hacia una homogeneización de la forma de pensamiento de una sociedad global?
2. TIPOS DE REDES POR SU DISPERSION
Al crear uan red, se toman en cuenta dos factores principales: el medio físico de transmisión y las reglas que rigen la transmisión de datos. Al primer factor le llamamos nivel físico y al segundo protocolos. En el nivel físico generalmente encontramos señales de voltaje que tienen un significado preconcebido. Esas señanles se agrupan e interpretan para formar entidades llamadas paquetes de datos. La forma como se accesan esos paquetes determinan la tecnología de transmisión y se aceptan dos tipos: "broadcast" y "point-to-point". Las redes de tipo "broadcast" se caracterizan porque todos los miembros (nodos) pueden accesar todos los paquetes que circulan por el medio de transmisión. Las redes punto a punto sólo permiten que un nodo se conecte a otro en un momento dado.
Por la extensión de las redes "broadcast" o "punto a punto", podemos clasificarlas de acuerdo a la tabla siguiente.
2.1 Redes de Area Local
Las redes de área local son el punto de contacto de los usuarios finales. Su finalidad principal es la de intercambiar información entre grupos de trabajo y compartir recursos tales como impresoras y discos duros. Se caracterizan por tres factores: extensión, su tecnología de transmisión y su topología.
2.1.1 Extensión de las redes de área local
Su extensión va de unos cuantos metros hasta algunos kilómetros. Esto permite unir nodos que se encuentran en una misma sala de cómputo, en un edificio, en un campus o una empresa mediana y grande ubicada en una misma locación.
2.1.2 Tecnologías de transmisión de las redes de área local
Las redes tradicionales operan con medios de transmisión tales como cable de par trenzado (Unshielded Twisted Pair), cables coaxial (ya casi obsoleto porque presenta muchos problemas), fibra óptica (inmune a la mayoría de interferencias), portadoras de rayo infrarojo o láser, radio y microondas en frecuencias no comerciales. Las velocidades en las redes de área local van desde 10 Megabits por segundo ( Mbps) hasta 622 Mbps.
2.1.3 Topologías de las redes de área local
La topología de una red se refiere a la forma que ésta
toma al hacer un diagrama del medio físico de transmisión
y los dispositivos necesarios para regenerar la señal o manipular
el tráfico. Las topologías generales son: anillo (ring),
dorsal (bus), dorsal dual (dual bus), estrella (star), árbol (tree)
y completas.
Las topologías de anillo, dorsal y árbol se adecuan mejor
para redes de tipo "broadcast" y el resto para redes de tipo punto a punto.
Los estándares más comunes son el IEEE 802.3 llamado Ethernet
y el IEEE 802.5 llamado Tojen Ring. Ethernet opera entre 10 y 100 Mbps.
En este estándard, todo nodo escucha todos los paquetes de está
red broadcast, saca una copia y examina el destinatario. Si el destinatario
es el nodo mismo, lo procesa y si no lo deshecha para escuchar el siguiente.
Para enviar un paquete escucha cuando el medio de transmisión esté
libre. Si ocurre que dos nodos enviaron un paquete al mismo tiempo, se
provoca una colisión y cada nodo vuelve a retransmitir su paquete
después de esperar un tiempo aleatorio. Token Ring opera entre 4
y 16 Mbps y utiliza una ficha (token) que permite enviar paquetes al nodo
que la posee mientras los otros escuchan. Una vez que un nodo termina de
enviar paquetes, pasa la ficha a otro nodo para que transmita.
2.2 Redes de Area Metropolitana
Una red de área metropolitana es una versión más grande de una LAN en cuanto a topología, protocolos y medios de transmisión que abarca tal vez a un conjunto de oficinas corporativas o empresas en una ciudad. Las redes deservicio de televisión por cable se pueden considerar como MANs y, en general, a cualquier red de datos, voz o video con una extensión de una a variuas decenas de kilómetros. El estándard IEEE 802.6 define un tipo de MAN llamado DQDB por sus siglas en inglés Distributed Queue Dual Bus. Este estándard usa dos cables half-duplex por los cuales se recibe y transmiten voz y datos entre un conjunto de nodos.
2.3 Redes de Area Amplia
Una red de área amplia se expande en una zona geográfica de un país o continente. Los beneficiarios de estas redes son los que se ubican en nodos finales llamados también sistemas finales que corren aplicaciones de usuario (por ejemplo, algún procesador de palabras o un navegador de WWW). A la infraestructura que une los nodos de usuarios se le llama subred y abarca diveros aparatos de red (denominados en general como routers o enrutadores) y líneas de comunicación que une a las redes de área local. El término de subred también se aplica a una técnica para optimixzar el tráfico en una red de área local de tamaño medio.
En la mayoría de las redes de área amplia se utilizan una gran variedad de medios de transmisión para cubrir grandes distancias. La transmisión puede efectuarse por microondas, por cable de cobre, fibra óptica o alguna combinación de los anteriores. Sin omportar el medio, los datos en algún punto se convierten e interpretan como una secuencia de unos y ceros para formar marcos de información (frames), luego estos frames son ensamblados para formar paquetes y los paquetes a su vez construyen archivos o registros específicos de alguna aplicación. Las redes clásicas se caracterizan porque utilizan routers para unir las diferentes LANs. Como en este caso los paquetes viajan de LAN en LAN a través de ciertas rutas que los routers establecen, siendo dichos paquetes almacenados temporalmente en cada router, a la subred que usa este pricipio se le conoce como punto-a-punto, almacena-y-envía o de enrutado de paquetes (point-to-point, store-and-forward, packet-switched).
Las topologías comunes en una red punto a punto son: de estrella, annilo, árbol, completa, anillos intersectados e irregular. La posibilidad de usar el aire como medio de transmisión nos da lugar a las redes inalámbricas. Se pueden construir usando estaciones de radio o satélites que envían ondas a diferentes frecuencias para enlazar los correspondientes enrutadores. Como el alcance de estas ondas no puede ser restringido en un cierto radio, se deben tomar algunas medidas especiales para no entrar en conflicto con otras ondas y para restringir el acceso.
2.4 Red Global Internet e internets
La red Internet es aquella que sa ha derivado de un proyecto del departamento de defensa de Estados Unidos y que ahora es accesible desde más de 2 millones de nodos en todo el mundo, y cuyos servicios típicos son las conexiones con emulación de terminal telnet , la transferencia de archivos ftp , el W W W , el correo electrónico , los foros de información globales NetNEWS .
Por otro lado, se consideran como internets (con la letra "i" minúscula) a aquellas redes públicas o privadas que se expanden por todo el mundo. El asunto interesante es que estas internets pueden valerse del Internet en algunos tramos para cubrir el mundo. La restricción mayor para que una red privada se expanda en el mundo usando Internet es que puede verse atacada por usuarios del Internet. Un esquema de seguridad para este caso puede ser que, para las LANs que conforman la internet privada, cada una de ellas encripte su información antes de introducirla a Internet y se decodifique en las LANs destinos, previo intercambio de las claves o llaves de decodificación. Este tipo de esquemas se pueden lograr con el uso de firewalls .
3. PROTOCOLOS DE COMUNICACION
Un protocolo es un conjunto de reglas que indican cómo se debe llevar a cabo un intercambio de datos o información. Para que dos o más nodos en una red puedan intercambiar información es necesario que menejen el mismo conjunto de reglas, es decir, un mismo protocolo de comunicaciones.
Debido a la gran variedad de protocolos, se hizo necesario estandarizarlos y para eso se tomó un diseño estructurado o modular que produjo un modelo jerárquico conocido como modelo de referencia OSI (Open Systems Interconnection).
3.1 Jerarquías de protocolos
La idea central detrás del modelo es que, para que una aplicación que reside en un nodo A establezca comunicación con una aplicación en un nodo B, debe usar los servicios de una capa de la red. Llamemos a esa capa "capa de aplicación". La capa de aplicación le brinda un conjunto de servicios a las aplicaciones pero a su vez depende de otra capa inferior para trabajar. Llamemos a esa capa "capa de transporte de paquetes". La capa de transporte de paquetes es todo lo que necesita la de aplicaión para trabajar en la red y, a su vez, la capa de aplicación es todo lo que necesita la de transporte para comunicarse con la aplicación, de manera que tenemos un flujo de información en ambos sentidos. Bajo la capa de transporte residen otras capas con relaciones similares a las ya descritas, hasta llegar a la capa que se encarga del problema del medio físico por el cual viaja finalmente la información de manera electrónica. Llamemos a esta última capa "capa física". Por ejemplo, esta capa podría encargarse de detectar señales de voltaje en un cable de cobre y agruparlas como unos y ceros para formar un byte, y luego unir los bytes hasta formar una cadena de cierto tamaño predefinido por el protocolo y pasar esa cadena a la capa inmediata superior.
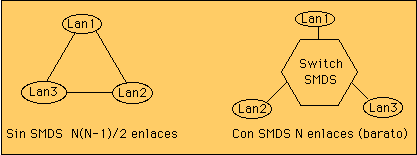
Los principios que rigen este diseño modular son:
Cada capa debe ser lo suficientemente pequeña para que sus funciones
sean fácilmente entendibles.
Cada capa debe ser lo suficientemente amplia para que realice un conjunto
de funciones que sean significativas para el protocolo en su conjunto.
Cada capa debe ofrecer un conjunto bien definido de funciones hacia
la capa superior.
Cada capa debe poder hacer su trabajo usando los servicios provistos
por la capa inferior.
En cada capa del modelo de referencia se puede hablar del protocolo
de la capa n y cada entidad que reside en una capa usa una interfase para
comunicarse con la capa inferior o con la capa superior. Esa interfase
consta de un conjunto de operaciones y servicios bien definidos según
los principios antes descritos. En un momento dado, se puede decir que
existe una comunicsción virtual directa entre la capa n de una aplicación
en un nodo con la capa n de otra aplicación en otro nodo.
Podemos decir que el conjunto de capas, sus principios y sus protocolos
definen una arquitectura de red. De esta forma es sencillo que un fabricante
produzca aparatos de red para algún nivel o niveles de la arquitectura
de red.
3.2 Aspectos de diseño
Dependiendo de las funciones y servicios que cada capa debe proveer y usar, se deben atacar algunos problemas interesantes al diseñar la arquitectura de red. En primer lugar, dado que en una red existen muchos nodos que quieren comunicarse entre sì, debe existir un mecanismo de direccionamiento que sea capaz de:
Identificar de manera única a una conexión que parte de
un nodo n a un nodo x que está siendo requerida por procesos en
dichos nodos.
Identificar de manera única para cada conexión a qué
tipo de servicio pertenece.
Si la interfase soporta mensajes de tamaño restringido, se debe
proveer un mecanismo de identificación de mensajes pequeños
que pertenecen a uno mayor.
Identificar en un mismo medio diferentes canales activos simultáneos.
Debido a que algunos medios físicos no están libres de
errores, se debe tener un mecanismo para detectarlos y en alguna de las
capas debe haber un mecanismo para corregir el error.
Debido a los medios no libres de errores, en el caso de no poder corregir
un error se debe pedir la retransmisión de datos.
Debido a que se puede perder la comunicación entre dos nodos,
debe existir un mecanismo para asignar un tiempo máximo de espera
en el envío o recepción de datos (timeout).
El protocolo debe contemplar la posibilidad de manejar un medio simplex,
half duplex o full duplex.
3.3 Interfases y servicios
Como ya vimos, cada capa tiene un conjunto de operaciones que realizar y un conjunto de servicios que usa de otra capa. De esta manera identificamos como usuario de servicio a la capa que solicita un servicio y como proveedor a quien la da. Cuando una entidad se comunica con otra ubicada en la misma capa pero en diferentes nodos se dice que se establece comunicación entre entidades interlocutoras (peer entities). Cada capa tiene un conjunto de servicio que ofrecer, el punto exacto donde se puede pedir el servicio se llama punto de acceso al servicio (Service Access Point, SAP). Por ejemplo, en el servicio telefónico se ofrecen conferencias persona a persona, el SAP es la roseta o jack donde se conecta el teléfono y la dirección es el número telefónico con quien se desea hablar. En cada capa, la entidad activa recibe un bloque de datos consistente de un encabezado que tiene significado para el protocolo de esa capa y un cuerpo que contiene datos para ser procesados por esa entidad o que van dirigidos a otra capa.
3.4 Relaciones entre servicios y protocolos
Las capas ofrecen servicios de dos tipos generales: orientadas a conexión y no orientadas a conexión y los servicios obtenidos cumplen con cierta calidad de servicio que puede ser un servicio confiable (reliable) o no confiable (non reliable).
3.4.1 Servicios orientados a conexión
Los servicios orientados a conexión se caracterizan porque cumplen tres etapas en su tiempo de vida:
Los servicios orientados a conexión pueden ser considerados como "alambrados", es decir, que existe un conexión alambrada entre los dos interlocutores durante el tiempo de vida de la conexión.
3.4.2 Servicios no orientados a conexión
Los servicios no orientados a conexión carecen de las tres etapas antes descritas y en este caso los interlocutores envían todos paquetes de datos que componen una parte del diálogo por separado, pudiendo éstos llegar a su destino en desorden y por diferentes rutas. Es responsabilidad del destinatario ensamblar los paquetes, pedir retransmisiones de paquetes que se dañaron y darle coherencia al flujo recibido. Los servicios no orientado a conexión se justifican dentro de redes de área local en donde diversos estudios han demostrado que el número de errores es tan pequeño que no vale la pena tener un mecanismo de detección y correción de los mismos.
3.4.3 Servicios confiables y no confiables
Se dice que un servicio es confiable si nos ofrece una transmisión de datos libre de errores. Para cumplir este requisito, el protocolo debe incluir mecanismos para detectar y/o corregir errores. La corrección de errores puede hacerse con información que está incluida en en un paquete dañado o pidiendo su retransmisión al interlocutor. También es común que incluya mecanismos para enviar acuses de recibo cuando los paquetes llegan correctamente.
Se dice que un servicio es no confiable si el protocolo no nos asegura que la transmisión está libre de errores y es responsabilidad del protocolo de una capa superior (o de la aplicación) la detección y corrección de errores si esto es pertinente o estadísticamente justificable. A un servicio que es a la vez no orientado a la conexión y no confiable se le conoce como "datagram service". Un servicio que es no orientado a la conexión pero que incluye acuse de recibo se le conoce como " acknowledged datagram service ". Un tercer tipo de servicio se le llama " request-reply " si consiste de un servicio no orientado a conexión y por cada envío de datos se espera una contestación inmmediata antes de enviar el siguiente bloque de datos. Este último servicio es útil en el modelo cliente-servidor. Los servicios no orientado a conexión se justifican dentro de redes de área local en donde diversos estudios han demostrado que el número de errores es tan pequeño que no vale la pena tener un mecanismo de detección y correción de los mismos.
4. EL MODELO DE REFERENCIA OSI
La Organización Estándares Internacionales (ISO por sus
iniciales en Inglés) emitió un modelo de referencia para
la interconexión de sistemas abiertos (Open Systems Interconnection
OSI) el cual formaliza el modelo prototipo explicado en secciones anteriores.
4.1 Capas del modelo de referencia
4.1.1 Capa Física
La capa física tiene que ver con el envío de bits en un medio físico de transmisión y se asegura de que si de un lado del medio se envía un 1 del otro lado se reciba ese 1. También tiene que ver con la impedancia, resistencia y otras medidas eléctricas o electrónicas del medio y de qué forma tiene (tamaño, número de patas) en conector del medio y cuáles son los tiempos aprobados para enviar o recibir una señal. También se toma en cuenta si el medio permite la comunicación simplex, half duplex o full duplex.
4.1.2 Capa de Ligado
En esta capa se toman los bits que entrega la capa física y los agrupa en algunos cientos o miles de bits para formar marcos de bits. Se puede hacer en este nivel un chequeo de errores y si no los hay enviar un marco de acuse de recibo (acknowledge). Para detectar los límites de un marco se predefinen secuencias de bits de control. Si un marco se pierde o daña en el medio físico este capa se encarga de retransmitirlo, aunque en ocasiones dicha operación provoca que un mismo frame se duplique en el destino, dado el caso es obligación de esta capa detectar tal anomalía y corregirla. También en esta capa se decide cómo accesar el medio físico.
4.1.3 Capa de Red
La capa de red se encarga de controlar la operación de la subred (medios físicos y dispositivos de enrutado). Una tarea primordial es decidir cómo hacer que los paquetes lleguen a su destino dados un origen y un destino en un formato predefinido por un protocolo. Otra función importante en este nivel es la resulocuón de cuellos de botella. En estos casos se pueden tener varias rutas para dar salida a los paquetes y en base a algunos parámetros de eficiencia o disponibilidad se eligen rutas dinámicas de salida. Otra función que se puede obtener en esta capa es el registro o reporte del tipo y cantidad de paquetes que circulan por el enrutador para efectos de cobro o de obtención de estadísticas.
4.1.4 Capa de Transporte
La obligación en esta capa es la de tomar datos de la capa de sesión y asegurarse que dichos datos llegan a su destino. En ocasiones los datos que vienen de la capa de sesión exceden el tamaño máximo de transmisión (Maximum Transmission Unit MTU) de la interfaz de red, por lo cual es necesario partirlos y enviarlos en unidades más pequeñas, lo cual da orígen a la fragmentación y ensamblado de paquetes cuyo control se realiza en esta capa. Una vez que esta capa se encarga de procesar datos de la capa de sesión y servir de interfase con la de red, podemos afirmar que su función es la de separar a las capas superiores de los posibles cambios en el hardware de red.
Otra función en esta capa es la de multiplexar varias conexiones que tienen diferentes capacidades de transmisión para ofrecer una velocidad de transmisión adecuada a la capa de sesión. Por ejemplo, se puede decidir en un momento dado que una conexión es muy cara y que mejor se multiplexe sobre una conexión existente más barata para tener un ahorro. Estas decisiones son transparentes para la capa de sesión. A partir de la capa de transporte (inclusive) las capas ofrecen servicios de interlocutor a interlocutor, esto es, que un programa de red en un nodo platica con otro programa similar en otro nodo de la red. En las capas inferiores esto no es posible ni requerido. La última labor importante de la capa de transporte es ofrecer un mecanismo de nombrado que sirva para identificar y diferenciar las múltiples conexiones existentes, así como determinar en qué momento se inician y se terminan las conversaciones; es decir, en esta capa hay un mecanismo de control de flujo. Por ejemplo, si el usuario "operador" en el nodo "A" quiere iniciar una sesión de trabajo remoto (telnet) en un nodo "B", existirá una conexión que debe ser diferenciada de la conexión que el usuario "luis" necesita para transferir un archivo (ftp) del nodo "B" al nodo "A".
4.1.5 Capa de Sesión
Esta capa ofrece el servicio de establecer sesiones de trabajo entre nodos diferentes de una red. Permite el transporte de datos (spoprtado por la capa de transporte) y añade algunas facilidades para el establecimiento del flujo de datos. Esta capa decide a quíen se le hace caso para transmitir datos entre las múltiples conexiones, una manera de hacerlo es proveer de fichas a los participantes de una conexión, de manera que aquél que tenga la ficha es el que puede transmitir (lo cual es útil en un medio half duplex). Otro servicio de esta capa es la sincronización y el establecimiento de puntos de chequeo. Por ejemplo, si se hace necesario transferir un archivo muy garnde entre dos nodos que tienen una alta probabilidad de sufrir una caída, es lógico pensar que una transmisión ordinaria nunca terminaría porque algún interlocutor se caerá y se perderá la conexión. La solución es que se establezcan cada pocos minutos un punto de chequeo de manera que si la conexión se rompe más tarde se pueda reiniciar a partir del punto de chequeo, lo cual ahorrará tiempo y permitirá tarde o temprano la terminación de la transferencia.
4.1.6 Capa de Presentación
La capa de presentación nos provee de facilidades para que podamos transmitir datos con alguna sintaxis propia para nuestras aplicaciones o para nuestro nodo. Existen computadoras que interpretan sus bytes de una manera diferente que otras (Big Endian versus Little Endian). En esta capa es posible convertir los datos a un formato independiente de los nodos que intervienen en la transmisión.
4.1.7 Capa de Aplicación
En esta capa se encuentran aplicaciones de red que nos permiten explotar los recursos de otros nodos. Dicha explotación se hace, por ejemplo, a través de una emulación de una terminal que trabaja en un nodo remoto, interpretando una gran variedad de secuencias de caracteres de contro que nos permiten desplegar en la terminal local los resultados, aún cuando éstos sean gráficos. Otra forma de explatación se da cuando transmitimos un archivo de una computadora que almacena sus archivos en un formato dado a una computadora de formato distinto. Es posible que el programa de transferencia realice las conversiones necesarias de manera que el archivo puede usarse inmediatamente bajo alguna aplicación.
4.2 Transmisión de datos en el modelo OSI
Un envío de datos típico bajo el model de referencia OSI comienza con una aplicación P en un nodo cualquiera de la red. P genera los datos D que quiere enviar a su contraparte en otro nodo. Le pasa los datos D a la capa de aplicación . La capa de aplicación toma los datos y los encapsula añadiendo un encabezado que contiene información de control o que puede estar vacío. El paquete completo resultante se lo pasa a la capa de presentación. La capa de presentación lo recibe y no intenta siquiera decodificar o separar los componentes del paquete, sino que lo toma como datos y le añade un encabezado con información de control de esta capa y el paquete resultante se lo envía a la capa de sesión. La capa de sesión recibe el paquete, que también son sólo datos para ella y le añade un encabezado de control. El resultado se lo envía a la capa de transporte. La capa de transporte recibe todo el paquete como datos y le añade su propio encabezado de control creando otro paquete que envía a la capa de red, la cual se encargará de enrutarlo a su destino apropiado, entre otras actividades que realiza. Las capas de red, ligado de datos y física toman, respectivamente, el paquete que les envía la capa superior y añaden a éste un encabezado definido por el protocolo que corresponde a cada capa y pasan el resultada a la capa inferior. La capa física traducirá el último paquete a las señales apropiadas para que viajen por el medio físico hasta el nodo destino.
En el nodo destino, la capa física toma los paquetes y les quita el encabezado de la capa física, pasando el paquete resultante a la capa de ligado de datos. La capa de ligado lo recibe y le quita el encabezado de esta capa, pasando el resultado a la capa de red, quien lo toma y le quita el encabezado de red, pasando el paquete a la capa de transporte que elimina el encabezado de transporte y pasa el resultado a la capa de sesión, quien también le quita el encabezado respectivo y pasa el paquete a la capa de presentación, que a su vez le quita el encabezado de presentación y le pasa el paquete a la capa de aplicación que, finalmente, le quita el último encabezado y le entrega el paquete de datos reales a la aplicación en el nodo destino. De manera virtual, se establecen conexiones directas entre las capas del mismo nombre de los dos diferentes nodos. Por ejemplo, el paquete que envía la capa de red es interpretado por la capa de red en el destino y no por otra capa. Para las capas inferiores de la de red, dicho paquete fue interpretado como datos, y para las capas superiores (transporte,sesión, presentación y aplicación) como un paquete compuesto de datos y encabezado.
Por otro lado, todas las capas, excepto la de aplicación, procesan
los paquetes realizando operaciones que sólo sirven para verificar
que el paquete de datos real esté íntegro o para que éste
llegue a su destino, sin que los datos por sí mismos sufran algún
cambio.
5. EL MODELO DE REFERENCIA TCP/IP
La Agencia de Proyectos de Investigación Avanzada del Departamento de Defensa de los Estados Unidos de Norteamérica definieron un conjunto de reglas que establecieron cómo conectar computadoras entre sí para lograr el intercambio de información, soportando incluso desastres mayores en la subred. Fue así como se definió el conjunto de protocolos de TCP/IP ( TCP/IP Internet Suite of Protocols). Para los años 80 una gran cantidad de instituciones estaban interesados en conectarse a esta red que se expandió por todo EEUU. La Suite de TCP/IP consta de 4 capas principales que se han convertido en un estándard a nivel mundial.
5.1 Las capas del modelo TCP/IP
Las capas de la suite de TCP/IP son menos que las del modelo de referencia OSI, sin embargo son tan robustas que actualmente une a más de 3 millones de nodos en todo el mundo. La capa inferior, que podemos nombrar como física respecto al modelo OSI, contiene varios estándares del Instituto de Ingenieros Electrónicos y Eléctricos (IEEE en inglés) como son el 802.3 llamado Ethernet que establece las reglas para enviar datos por cable coaxial delgado (10Base2), cable coaxial grueso (10Base5), par trenzado (10Base-T), fibra óptica (10Base-F) y su propio método de acceso, el 802.4 llamado Token Bus que puede usar estos mismos medios pero con un método de acceso diferente, el X.25 y otros estándares denominados genéricamente como 802.X.
La siguiente capa cumple, junto con la anteriormente descrita, los niveles del modelo de referencia 1,2 y 3 que es el de red. En esta capa se definió el protocolo IP también conocido como "capa de internet". La responsabilidad de este protocolo es entregar paquetes en los destinos indicados, realizando las operaciones de enrutado apropiadas y la resolución de congestionamientos o caídas de rutas.
La capa de transporte es la siguiente y está implantada por dos protocolos: el Transmission Control Protocol y el User datagram Protocol. El primero es un protocolo confiable (reliable) y orientado a conexiones, lo cual significa que nos ofrece un medio libre de errores para enviar paquetes. El segundo es un protocolo no orientado a conexiones (connectionless) y no es confiable (unreliable). El TCP se prefiere para la transmisión de datos a nivel red de área amplia y el otro para redes de área local.
La última capa definida en la suite de TCP/IP es la de aplicación y en ella se encuentran decenas de aplicaciones ampliamente conocidas actualmente. Las más populares son el protocolo de transferencia de archivos (FTP), el emulador de terminales remotas (Telnet), el servicio de resolución de nombres (Domain Name Service DNS), el WWW, el servicio de correo electrónico (Simple Mail Transfer Protocol SMTP), el servicio de tiempo en la red (Network Time Protocol NTP), el protocolo de transferencia de noticias (Network News Transfer Protocol NNTP) y muchos más.
5.2 Comparación con el modelo OSI
El model TCP/IP no tiene bieen divididas las capas de ligado de datos, presentación y sesión y la experiencia ha demostrado que en la mayoría de los casos son de poca utilidad [Tan96]. Los estándares 802.X junto con el protocolo IP realizan todas las funciones propuestas en el modelo OSI hasta la capa de red. Los protocolos TCP y UDP cumplen con la capa de transporte. Finalmente, las aplicaiones ya mencionadas son ejemplos prácticos y reales de la funcionalidad de la capa de aplicación.
5.2.1 Tipos de Comunicaciones
El modelo OSI propone tener comunicaciones orientadas y no orientadas a conexión en la capa de red, mientras que TCP/IP sólo ofrece no orientadas a conexión, mientras que OSI propone en el nivel de transporte comunicaciones orinetadas a conexión mientras que TCP/IP ofrece orientadas y no orientadas a conexión en dicha capa. [Tan96].
5.2.2 Críticas al modelo OSI
El modelo OSI tiene siete niveles que fueron propuestos debido a que IBM tenía su protocolo de siete capas SNA (Systems Network Architecture) y el comité no quiso ir contra la corriente peleando contra la preponderancia de IBM en esos días [Tan96]. Por otro lado, mientras se planeaba y discutía el modelo OSI, ya se estaba trabajando y creando redes usando TCP/IP, de manera que al estar disponible el trabajo del modelo OSI la mayoría de las compañías ya no quiso hacer el esfuerzo de migrar sus productos. En general, las críticas más importantes al modelo OSI y sus implantaciones se pueden resumir en los siguientes puntos [Tan96]:
El conjunto total de la pila de protocolos resultó sere demasiada
compleja para entender e implantar.
Las capas contienen demasiadas actividades redundantes, por ejemplo,
el control de errores se integra en casi todas las capas siendo que tener
un único control en la capa de aplicación o presentación
sería suficiente.
La enormidad de código que fue necesario para implantar el modelo
OSI y su consecuente lentitud hizo que la palabra OSI se asociara a "calidad
pobre", lo cual contrstó con TCP/IP que se implantó exitosamente
en el sistema operativo UNIX y era gratis.
OSI tuvo poca aceptación en EEUU porque la mayoría de
la gente pensó que era un estándard implantado por la comunidad
europea, y todos sabemos que la tecnología o deporte que no es inventado
en EEUU es discriminada rápidamente.
5.2.3 Críticas al modelo TCP/IP
El modelo TCP/IP primero fue llevado a la práctica y luego fue descrita su funcionalidad, por lo cual se acepta que no puede usarse para describir otros modelos. Las críticas en general se resumen a continuación:
El modelo no distingue bien entre servicios, interfaces y protocolos, lo cual afecta el diseño de nuevas tecnologías en base a TCP/IP. Las capas que le faltan con respecto al modelo OSI ni siquiera se mencionan y eso es lógico porque TCP/IP fue un predecesor de OSI. No se puede hablar propiamente de un modelo TCP/IP, pero se tiene que discutir acerca de él forzados por su uso en todo el mundo. Algunos de los protocolos de TCP/IP fueron creados por estudiantes y para solucionar problemas viejos y las necesidades modernas requieren de otros protocolos.
Conluyendo, el modelo OSI es muy bueno como marco teórico para describir la funcionalidad de los dispositivos y protocolos que hacen funcionar una red, pero se acepta que las capas de sesión y presentación no son muy útiles [Tan96], por lo cual generalmente se usa un modelo reducido con las capas física, ligado de datos, red, transporte y apicación.
5.3 Programación en red usando sockets bajo UNIX.
Los aprendices de UNIX muchas veces encontramos conceptos y facilidades que son difíciles de aprender en primera instancia. Uno de esos conceptos es la facilidad de SOCKETS. En este tutorial se explica qué son, cómo se usan y se muestran ejemplos de código fuente para su uso correcto.
Una Analogía ¿ Qué es un socket?
El socket es el método de BSD para llevar a cabo la comunicación entre procesos (Interprocess Communication o IPC). Esto quiere decir que un socket se usa para permitir que un proceso pueda platicar o intercambiar información con otro, de una manera muy parecida a cómo se usa una línea telefónica entre dos personas. La analogía del teléfono es buena, y será usada en repetidas ocasiones para describir el comportamiento de un socket.
Instalación de un Nuevo Teléfono ¿ Cómo escuchar en la red por conexiones de socket ?
Para que una persona reciba llamadas telefónicas, primero necesita tener una línea instalada. Para que un socket pueda aceptar peticiones primero debe crearse el socket. Para crear el socket se deben seguir algunos pasos. El primero es preparar el lugar para poner el teléfono, en este caso, debemos hacer el socket con el comando socket() . Como los sockets pueden crearse de varios tipos, debemos especificar de qué tipo lo queremos al crearlo. Una opción es indicar el formato de direccionamiento del socket. Así como el correo electrónico usa un esquema diferente para entregar correspondencia a como un teléfono funciona para lograr la comunicación, asi pueden diferir los sockets. Los dos esquemas más comunes de direccionamiento son AF_UNIX y AF_INET . El direccionamiento AF_UNIX usa senderos ( pathnames ) para identificar a los sockets y son muy útiles para la comunicación entre procesos en una misma computadora. El otro esquema, AF_INET usa direcciones de Internet (Internet Protocol Addresses o Direcciones IP) que consisten en cuatro números decimales escritos de la forma #1.#2.#3.#4, por ejemplo, (140.148.101.26). Además, cada computadora con una dirección IP puede manejar varios tipos de conexiones al mismo tiempo, cada una de ellas en un puerto distinto. Otra opción que debemos proveer cuando creamos un socket es el tipo de socket, que indique cómo preferimos que los datos viajen por la red. Los dos tipos más comunes son SOCK_STREAM y SOCK_DGRAM . La opción SOCK_STREAM indica que los datos viajan por la red como una secuencia de letras una tras otra, mientras que SOCK_DGRAM indica que los mismos lo harán en grupos (llamados datagramas). Nosotros preferiremos SOCK_STREAM.
Después de crear un socket, debemos darle una dirección para que escuche llamadas, así como nosotros damos nuestro número telefónico a nuestros conocidos para que nos llamen. La función bind() es usada para hacer esta tarea. Los sockets de tipo SOCK_STREAM tienen la capacidad de encolar llamadas pendientes cuando estamos ocupados en atender una llamada en particular. La función listen() es usada para establecer el máximo número de llamadas que somos capaces de encolar. Aunque no es obligatorio invocar o usar a listen(), es muy recomendable hacerlo para procesar llamadas pendientes.
Las siguientes funciones muestran cómo usar socket(), bind() y listen() para establecer un socket que acepta llamadas:
/* código para establecer un socket;
original de bzs@bu-cs.bu.edu
*/
int establece(num_puerto)
u_short num_puerto;
{ char minombre[MAXHOSTNAME+1];
int s;
struct sockaddr_in sa;
struct hostent *hp;
bzero(&sa,sizeof(struct sockaddr_in)); /*
limpia nuestra direccion*/
gethostname(minombre,MAXHOSTNAME); /*Obtengo
mi nombre */
hp= gethostbyname(minombre); /* Determina nuestra
información */
if (hp == NULL) /* Aborto si no existo!! */
return(-1);
sa.sin_family= hp->h_addrtype; /* Esta es nuestra
direccion*/
sa.sin_port= htons(num_puerto); /* Este es nuestro
puerto */
/* crea socket */
if ((s=socket(AF_INET,SOCK_STREAM,0))<0)
return(-1);
if (bind(s,&sa,sizeof sa,0) < 0) {
close(s);
return(-1); /* Asigna la dirección al
socket */
}
listen(s, 3); /* Encolo hasta 3 llamadas */
return(s);
}
Después de que creamos el socket, debemos esperar que alguien nos llame. La función accept() es usada para hacer esto. Esta función esperara a que alguien llame y cuando esto sucede, accept() hace una copia del teléfono original y nos la entrega. El teléfono original se queda esperando otra llamada.
La siguiente función puede ser usada para aceptar una llamada en un socket:
int descuelga_tel(s)
int s; /* s es un socket creado con establece()
*/
{ struct sockaddr_in isa; /* dirección
del socket */
int i; /* tamano de la dirección */
int t; /* socket de la conexion */
i = sizeof(isa); /* obtiene el tamano */
getsockname(s, & isa,&i); /* obtiene
el nombre del socket */
if ((t = accept(s, & isa,&i)) < 0)
/* acepta la llamada y duplica */
return(-1);
return(t);
}
Así como en una central telefónica se reciben llamadas que son delegadas a una persona mientras la recepcionista se queda esperando nuevas llamadas, en UNIX usamos la función fork() para crear un nuevo proceso que atienda la llamada actual. El siguiente código muestra cómo usar la función establece() y descuelga_tel() para controlar varias conexiones simultáneas:
#include <errno.h> /* Encabezados necesarios*/
#include <signal.h> /* vea "man bind" */
#include <stdio.h> /* vea "man listen */
#include <sys/types.h> /* vea "man accept
*/
#include <sys/socket.h>
#include <sys/wait.h>
#include <netinet/in.h>
#include <netdb.h>
#define PORTNUM 50000 /* Puerto donde vamos a escuchar */
void bomberazo(), haz_algo();
main()
{ int s, t;
if ((s= establece(PORTNUM)) < 0) { /* instala
el teléfono */
perror("establece");
exit(1);
}
signal(SIGCHLD, bomberazo); /* Para eliminar "zombis" */
for (;;) { /* Ciclo infinito para llamadas*/
if ((t= descuelga_tel(s)) < 0) { /* alguien
llama */
if (errno == EINTR) /* error EINTR en accept()
*/
continue; /* darle chance de intentar */
perror("accept"); /* otra vez */
exit(1);
} /* Delegar esta llamada */
switch(fork()) {
case -1 : /* No se pudo delegar llamada */
perror("fork");
close(s);
close(t);
exit(1);
case 0 : /* Ya pude delegar, atiendo la */
haz_algo(t); /* llamada con haz_algo(). */
exit(0);
default : /* Soy la telefónista, espero
*/
close(t); /* por otra llamada */
continue;
}
}
}
/* Como atiendo llamadas delegadas, una vez que
fueron atendidas
* finiquito a quien la atendió (que es
un proceso hijo)
*/
void bomberazo()
{ union wait wstatus;
while(wait3(&wstatus,WNOHANG,NULL) >= 0);
}
/* Esta función haz_algo() es la que va
a leer la información que
* produzca la llamada. Puede ser, por ejemplo,
guardar en un
* archivo los datos, desplegarlos en pantalla
o cualquier otra
* cosa.
*/
void haz_algo(s)
int s;
{
/* código tuyo para manipular la información
recibida
:
:
*/
}
Haciendo la Llamada ¿Cómo llamar en el socket?
Ahora ya sabemos cómo crear un socket en el cual despachar llamadas. Así que, ¿Cómo hacemos llamadas sobre ese socket ? Los pasos para realizar una llamada es similar a como las escuchamos. Primero necesitamos el teléfono para hacer la llamada, es decir, necesitamos crear el socket. Para crearlo, usamos la función socket(). Después de conseguir el teléfono (socket), tratamos de marcar el número asignandole la dirección al socket e invocando a la función connect() . La siguiente función intenta hacer una llamada a un socket particular.
int marca_número(hostname, num_puerto)
char *hostname;
{ struct sockaddr_in sa;
struct hostent *hp;
int a, s;
/* verificamos nombre */
if ((hp= gethostbyname(hostname)) == NULL) {
errno= ECONNREFUSED; /* y dirección */
return(-1); /* error, salimos */
}
bzero(&sa,sizeof(sa)); /* limpiamos estructura*/
/* pon dirección */
bcopy(hp->h_addr,(char*)&sa.sin_addr,hp->h_length);
sa.sin_family= hp->h_addrtype;
sa.sin_port= htons((u_short)num_puerto);
/* crea socket */
if ((s= socket(hp->h_addrtype,SOCK_STREAM,0))
< 0)
return(-1);
if (connect(s,&sa,sizeof sa) < 0) { /*
conexión */
close(s);
return(-1);
}
return(s);
}
Esta función regresa un teléfono (socket) ya conectado a través del cual los datos ya pueden fluir.
Conversación ¿Cómo hablar entre sockets?
Ahora que ya tenemos una conexion hecha con sockets queremos enviar datos entre ellos. Las funciones read() y write nos servirán para realizar la lectura y escritura de los mismos. La diferencia de usar las funciones read() y write() con archivos abiertos a usarlas con sockets es el número de bytes que la función regresa. Con un archivo, read() lee los bytes que se especifiquen en sus argumentos, y write() escribe tambien lo indicado en los argumentos. En un socket, esas funciones leerán o escribirán los bytes que esteén disponibles en ese momento, de manera que para leer o escribir el número deseado, es necesario realizar un ciclo de lecturao escritura hasta llegar al número deseado de bytes. Una función muy simple que realiza el ciclo mencionado se muestra enseguida:
int lee_datos(s,buf,n)
int s; /* s = socket ya conectado */
char *buf; /* buf = apuntador a un arreglo de
letras */
int n; /* n = número de bytes que deseamos
leer */
{ int cnt, /* cnt = bytes leidos en un instante
dado */
br; /* br = bytes leidos en un paso */
cnt= 0;
br= 0;
while (cnt < n) { /* ciclo de lectura */
if ((br= read(s,buf,n-cnt)) > 0) {
cnt += br; /* incrementa bytes leidos */
buf += br; /* mueve el apuntador del buffer */
}
if (br < 0) /* si no se puede leer mando -1
*/
return(-1);
}
return(cnt);
}
Una función similar debería usarse para la escritura de datos, pero se deja al lector ese ejercicio para que se divierta, y haga algo!
Colgando el teléfono ¿Cómo deshacerse de un socket después de usarlo) ?
Igual que colgamos el teléfono cuando terminamos una llamada, necesitamos cerrar la conexion que se hizo entre sockets. Para esta labor se usa la función close() , la cual debe invocarse en cada lado del socket. Si un extremo del socket es cerrado y en el otro se intenta leer o escribir, el sistema enviará un mensaje de error.
Hablando un Mismo Lenguaje (El orden de los bytes es importante)
Ahora que podemos hacer que dos computadoras platiquen entre ellas debemos
tener cuidado en cómo se transmiten la informacion. Sabemos que
hay diferentes formas de codificar los datos, por ejemplo usando un código
ASCII o un código EBCDIC. Otro aspecto es que una misma cadena de
7 u 8 bits puede ser interpretada de dos formas diferentes: que el bit
0 sea el mas significativo y el bit 7/8 sea el menos significativo, o viceversa.
Es el famoso problema de maquinas "BIG-ENDian" y "LITTLE-ENDian". Así
que si comunicamos una máquina BIG-END con una LITTLE-END, es posible
que un conjunto de bytes signifiquen cosas diferentes para una y otra.
Para atacar el problema del orden de bytes se usan las funciones ntohs()
(netork to host short integer), htons (host to network short integer),
htoni() (host to network integer),
htonl() (host to network long integer) y ntohl() (network to host long
integer). Por ejemplo, para poder enviar un número entero a través
de un socket en la red, primero le aplicamos la función host to
network integer htoni() como se muestra enseguida.
i= htoni(i);
escribe_datos(s, &i, sizeof(i));
Y después de leer un entero de la red, debemos convertirlo con ntohi():
lee_datos(s, &i, sizeof(i));
i= ntohi(i);
Es recomendable seguir el hábito de usar estas funciones para evitar problemas del orden de bytes.
El Futuro esta en tus manos ¿Qué hacer ahora?
Usando lo que ya se ha discutido aquí debe ser suficiente para construir nuestros propios programas de comunicación con sockets. Como con todas las cosas nuevas, es buena idea revisar el código de programas ya hechos para dilucidar su funcionamiento o la aplicación novedosa de esta tecnología. Existen muchos programas de dominio publico que usan el concepto del socket y hay muchos libros que los exploran con mucha mas profundidad de lo que aqui se hace. Al final de este documento se anexan el código de un servidor y de un cliente que usan sockets. Realizan una función muy sencilla. El servidor escucha llamadas en un puerto dado y cualquier información que reciba la vuelve a escribir al socket hacia el cliente, es decir, responde la llamada repitiendo lo que le dicen. Por otro lado, el cliente lee un renglón de texto del teclado y se lo envía al servidor, y escribe en la pantalla todo aquello que el servidor le responda.
6. EJEMPLOS DE REDES
En las siguientes cuatro secciones daremos un
vistazo a los aspectos más importantes de cuatro redes diferentes
lo cual nos abrirá el panorama en cuanto a su utilidad, sus funciones,
y sus objetivos.
6.1 Vistazo a Novell Netware
En nuestro país, en la gran cantidad de microempresas, las necesidades en cuanto a compartir información y recursos (archivos, impresoras, bases de datos, etc.) se ve ampliamente satisfecha por el sistema comercial Novell Netware ® . Esta pila de protocolos está basada en el Sistema de Red Xerox (Xerox Network System XNS) con algunas modificaciones.
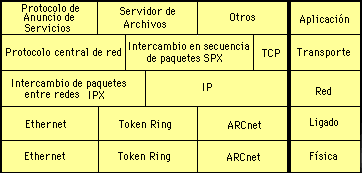
Los niveles físico y de ligado de datos pueden escogerse entre varios estándares comerciales como son Ethernet, Token Ring y ARCnet. El nivel de red trabaja con un protocolo no confiable (unreliable) y no orientado a conexión (connectionless) llamado IPX (Internetwork Packet eXchange). Este protocolo pasa los paquetes de un origen a su destino aun cuando pertenezcan a redes diferentes, lo cual es una forma de trabajar similar a la que realiza el protocolo IP (el cual también está disponible bajo NetWare), con la diferencia de que IP usa direcciones de 4 bytes mientras que IPX las tiene de 10 bytes. Esta amplitud es una buena estrategia porque permite tener bajo este protocolo a una gran cantidad de nodos que supera a la cantidad que pueden estar bajo TCP/IP, lo cual se ha vuelto crítico en los 90's porque se está llegando al punto de saturación. La capa de transporte ofrece los procolos SPX y NCP (Network Core Protocol). NCP es un protocolo orientado a conexión y es, de hecho, el corazón de NetWare. SPX también está disponible aunque sólo ofrece el servicio de transporte. Por ejemplo, el programa Lotus Notes utiliza SPX para tranbajar en red, mientras que el servidor de archivos utiliza NCP.
Al igual que en TCP/IP, aquí no existen las capas de sesión y presentación. La capa de aplicación contiene varios protocolos, tales como:
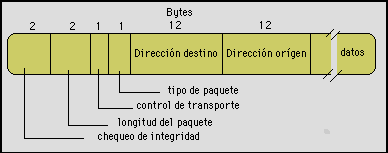
Al igual que en TCP/IP, un paquete de red es la clave para construir todo sobre él. Un paquete típico de IPX contiene el orígen, destino, datos e información de control tal como dos bytes para checar si el paquete está íntegro. Otra información de control es un byte que indica cuántas redes diferentes ha atravesado el paquete, si el paquete ha traspasado un límite de redes se descarta. La dirección origen y destino está compuesta de 4 bytes para el número de red, 6 bytes para el número de nodo y 2 bytes para indicar el socket del nodo. Cuando un nodo en la red es encendido, envía un mensaje broadcast preguntando si existe algún servidor disponible. En los nodos de ruteo existen agentes que controlan una base de datos construida con los servicios ofrecidos a través de mensajes broadcast de los protocolos de anuncio de servicios. Estos agentes responden a los nodos cliente, entoces ya se puede establecer una comunicación directa entre un cliente y un servidor para negociar operacines sobre archivos, impresoras y otros recursos. El cliente puede seguir preguntando acerca de otros servidores dependiendo del servicio necesitado.
6.2 Vistazo a ARPANET
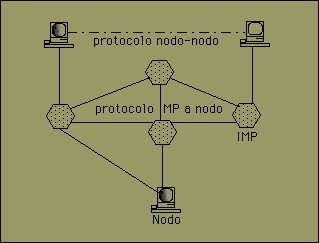
Arpanet nació como una red dedicada al servicio del Departamento de Defensa de los Estados Unidos de Norteamérica, cuyo propósito era crear un medio de comunicación alterno y diferente al sistema telefónico tradicional. Se decidió que si el sistema telefónico era una red de tipo "circuit switched", en la cual si una central era dañada las conversaciones no tendrían forma de continuar debido a que se interrumpían las conexiones punto a punto, entonces una red donde los datos de la comunicación pudieran ser divididos en paquetes y éstos viajar de manera independiente (incluso por rutas diferentes), cuando un elemento de intercambio (switcheo) se dañara, el paquete podría ser retransmitido por una ruta alterna, lo cual constituye una red de tipo "packet switched". Las ventajas de este nuevo tipo de red fue adoptada por el Departamento de Defensa y se conoció como Arpanet. El Arpanet se concibió como una "subred" (conjunto de dispositivos de red que conforman el medio físico de comunicación entre nodos) y un conjunto de nodos que intercambiaban información.
Cada nodo estaba conectado a otros dos elementos: otro nodo o algún elemento de la subred. Se necesitaron dos protocolos: un protocolo nodo a nodo y otro de nodo a IMP (Interface Message Processor). Para diciembre de 1969 se conectaron los primeros cuatro nodos: UCLA, SRI, UCSB y la Universidad de Utah y en tres años creció más del 1000% expandiéndose por todo el país. También se inventaron los primeros servidores de terminales (en aquel tiempo Terminal Interface Processor) e IMP que soportaban a varios nodos al mismo tiempo. Posteriormente se creó la suite de protocolos de TCP/IP para hacer más robusta y eficiente la infraestructura de Arpanet, y la Universidad de Berkeley la incluyó en el sistema operativo UNIX. Este pasó tuvo un efecto espectacular, ya que el BSD 4.2 se podía instalar relativamente fácil en las DEC VAX que pululaban en muchas universidades y empresas, lo cual le dio un gran impulso a Arpanet. Para 1983 había más de 200 IMPs en la red y ARPA decidió dejar su adminitración en manos de la Agencia de Comunicaciones de la Defensa, y el primer paso tomado fue dividir la sección militar de la sección civil. A la sección militar se le nombró MILNET que conservó líneas de comunicación con la sección civil.
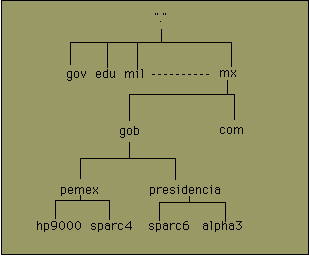
Debido al éxito alcanzado por Arpanet, cientos de instituciones con redes de área local ya existentes desearon formar parte de esta red más amplia, y este deseo se realizó durante los 80s, lo cual provocó la necesidad de contar con un mecanismo para accesar amigablemente cualquier nodo de la red, y se decidió una forma jerárquica de nombrado en base a "dominios".
Por ejemplo, para México, existe el dominio superior MX, del cual existen varios subdominios como son GOB y COM. Bajo GOB encontramos PEMEX. De esta forma, el dominio de PEMEX es PEMEX.GOB.MX y debajo de él encontramos nodos reales como podrían ser las computadoras con nombre hp9000 y sparc4. Para que los servicios de TCP/IP puedan ser efectivos, se necesita traducir el nombre completo del nodo (por ejemplo hp9000.pemex.gob.mx) a una dirección IP tal como 160.23.7.5. Esta traducción es realizada por un Servidor de Nombres dentro del servicio denominado Sistema de Nombres de Dominio (Domain Name System DNS).
6.3 Vistazo a NFSNET
El éxito de Arpanet hizo que muchas universidades, a principios de los 80s y a través de la Fundación Nacional de Ciencias (NSF de Estados Unidos) crearan una red denominada CSNET la cual accesaba a Arpanet a través de un nodo de BBN (la institución que diseñó los primeros protocolos nodo-nodo y nodo-IMP). Para 1984 la NSF diseñó una red que unía seis supercomputadoras a través de seis computadoras de bajo rendimiento con líneas privadas a 56Kbps. Lo interesante del diseño es que el protocolo de red fue TCP/IP desde el inicio creando así la primer red de área amplia con este protocolo. Posteriormente se añadieron otras instituciones (museos, universidades,etc.) y redes locales para accesar a las supercomputadotras, todo lo cual creó la NSFNet la cual tenía una conexión a Arpanet a través de un enlace en la Universidad de carnegie Mellon. El gobierno de Estados Unidos decició, para 1990, ya no financiar redes por lo cual algunas empresas privadas como MCI, MERIT e IBM tomaron el relevo de la NSFNet e incrementaron su velocidad de 1.5 Mbps a 45 Mbps la cual se denominó ANSNet (Advanced Networks and Services Net). Para 1995, el tronco de NSFNet fue innecesario porque existían numerosas redes comerciales que lo hacían, y cuando ANSNet fue vendidad a la empresa America Online, NSF promovió que cuatro operadores de red aseguraran que las redes regionales de Estados Unidos pudieran conectarse unas con otras a través de varios Puntos de Acceso de Red. Los operadores fueron PacBell en San Francisco, Ameritech en Chicago, MFS en Washington, y Sprint cerca de Nueva York. La condición para ser operador era ofrecer que cualquier red regional pudiera conectarse a cualquier NAP y que el cliente pudiera escoger en base a calidad y precio. Aparte de estos NAPs, algunos otros de tipo gubernamental y privados se sumaron creando una red de autopistas de información competitivas.
6.4 Vistazo a Internet
La sinergia de la unión de NSFNet y Arpanet hizo que el crecimiento de la red fuera exponencial. Algunas personas desde los 80s veían la unión de redes como una red global o internet y más tarde como la Internet. En 1990 Internet contaba con 3000 redes y cerca de 200,000 nodos. Ya en 1992 tenía un millón y en 1995 había decenas de millones de nodos, y se calcula que cada año el número se duplica. Este crecimiento se explica porque muchas redes de área local que crecieron fuera de Internet ahora se están conectando a ella. Se considera que un nodo pertenece a Internet si puede enviar paquetes del protocolo TCP/IP y alcanzar a otros nodos dentro de la misma. Los servicios típicos ofrecidos en Internet son el correo electrónico (a través de un servidor de correo y un lector de correo como pine, eudora, algún navegador de WWW con esta capacidad, etc.), el servicio de noticias de red NEWS (a través de un servidor de NetNews y un lector como el xvnews, tin, nnews, etc.), la ejecución remota de comandos y las seiones de trabajo remotas (a través del comando de UNIX rlogin o bien con el programa telnet), la transferencia de archivos (a través del File Transfer Protocol donde los servidores de FTP anónimos son esenciales), y el WWW (World Wide Web).
7. EJEMPLOS DE SERVICIOS
En 1997 los usuarios mexicanos podemos escoger entre varios operadores de servicio telefónico de larga distancia, los cuales han instalado varios miles de kilómetros de fibra óptica a través del país conformando una red disponible al público. Se están promoviendo protocolos bajo esta infraestructura como son Frame Relay, Fast Ethernet y ATM entre otros.
7.1 SMDS
Este servicio (Switched Multimegabit Data Service) es apropiado cuando:
SMDS cuenta con una serie de facilidades adicionales como son:
SMDS es un servicio no orientado a la conexión y no confiable (connectionelss, non reliable). Su formato interno consta de tres campos principales: Dirección origen, Dirección destino y datos. El campo de datos puede contener hasta 9188 bytes que puede ser un paquete de cualquier protocolo.
La funcionalidad de SMDS reside en aparatos (switches) con una velocidad de transferencia estándard de 45Mbps. Para una colección de N LANs, se necesitarían N enlaces hacia el switch el cual le dará conectividad a todas las LANs a la velocidad que el cliente esté dispuesto a pagar.
7.2 X.25
El conjunto de protocolos X.25 se usa en una gran cantidad de redes públicas en todo el mundo para conectar LANs privadas a redes públicas de datos. Desde el punto de vista de X.25, la red funciona como lo hace el sistema telefónico. En X.25, cada host se conecta a un switch que tendrá la obligación de enrutar los paquetes de los diferentes enlaces. Para comprender mejor esto, veamos una compraración de X.25 contra el modelo de referencia OSI.

X.25 es un servicio orientado a la conexión y ofrece circuitos virtuales y permanentes. Un circuito conmutado virtual se crea cuando un nodo envía un paquete a la red pidiendo llamar a un nodo remoto. Se establece una ruta desde el nodo remitente al nodo destino y por ahí se transmiten los paquetes que generalmente llegan en orden. En los niveles 2 y 4 se checan errores de transmisión. X.25 también realiza un control de flujo que asegura que los paquetes no serán perdidos si hay una diferencia de velocidad de transmisión/recepción entre emisor y receptor. Un circuito virtual permanente es igual que el conmutado, excepto que existe una línea física entre emisor y receptor y la llamada inicial del nodo a la red es innecesaria. X.25 es interesante para personas que requieren acceso a LANs desde lugares remotos a través del servicio telefónico público. El servicio de PAD (Packet Assembler Disassembler) es útil y se realiza entre una terminal que hable X.25 (descrito en un documento llamado X.3). Otro protocolo llamado X.28 define la comunicación entre la terminal y el PAD, mientras el protocolo X.9 la define entre el PAD y la red. Al X.3, X.28 y X.29 se le conoce como triple X.
7.3 Frame Relay
El servicio de Frame Relay nació con los cambios tecnológicos, ya que ahora las computadoras y el servicio telefónico son más baratos. Frame Relay se basa en la existencia de líneas telefónicas privadas, digitales y con pocos errores. El cliente renta una línea privada entre dos nodos y puede enviar información a una velocidad estándard de 1.5 Mbps (contra una velocidad estándard de X.25 de 64Kbps). También es posible la transmisión con circuitos virtuales conmutados y enviar marcos de 1600 bytes a diferentes destinos, para lo cual se usan paquetes que llevan la dirección destino (consumiendo 10 bits). El uso de circuitos virtuales conmutados es más barato en general que una línea privada. Frame Relay es una competencia para X.25, sus ventajas son:
Opera a una velocidad estándard mayor (1.5 Mpbs contra 64Kbps)
El protocolo es más moderno y acorde a la tecnología actual
Tiene menos sobrecarga porque no realiza chequeo de errores
Tiene menos sobrecarga porque no tiene control de flujo
Sus desventaja contra X.25 son:
Le deja a la aplicación el realizar el control de errores
No es tan robusto como X.25
No tiene control de flujo
Tiene un modo muy simple de indicar errores (un bit de error)
7.4 ATM
Hasta ahora hemos visto protocolos y servicios que sirven pricipalmente la transmisión de datos. Una necesidad que está surgiendo desde hace algunos años es la de poder transmitir imágenes, audio, video y datos por un mismo canal físico. Debido a lo anterior, nació el proyecto de Broadbad Integrated Services Digital Network (B-ISDN) que pretende ofrecer la transmisión de datos, voz, señales de televisión, música estéreo, etc. sobre la red pública telefónica. La tecnología que soporta este proyecto es ATM (Asynchronous Transfer Mode).

ATM trabaja con el concepto de celda. Para transmitir cualquier tipo de información utiliza paquetes de tamaño fijo de 53 bytes, de los cuales 5 son de control y 48 de información (payload). El servicio es orientado a la conexión y su velocidad de transmisión es de 155 Mbps (velocidad para televisión de alta definición) hasta 622 Mbps. El modelo de referencia B-ISDN ATM consta de tres capas principales. La capa física define y se encarga de los niveles de voltaje del nivel físico y de determinar el comienzo y fin de una cadena de bits en el tiempo. La capa física no se restringe a un tipo específico de medio de transmisión físico, por lo cual existe la subcapa física dependiente del medio físico, la cual se encarga de dar acceso a la red física. La subcapa de convergencia de transmisión se encarga de manejar celdas lo cual sería el trabajo de crear frames en el nivel de ligado ISO. La segunda capa, la capa de ATM, se encarga de solucionar la congestión de tráfico, de darle significado a los encabezados de las celdas y la creación y liberación de circuitos. La capa más interesante es la de adaptación, ya que esta capa funciona diferente de acuerdo al tipo de información que las celdas contienen. La capa de Adaptación está dividida en dos. La capa inferior se encarga de re-ensamblar celdas para crear paquetes de tamaño mayor según lo requiera la aplicación que se encuentra en capa superiores. La capa superior se encarga de decidir qué tipo de servicio requiere nuestra aplicación (video, voz, datos, etc.)
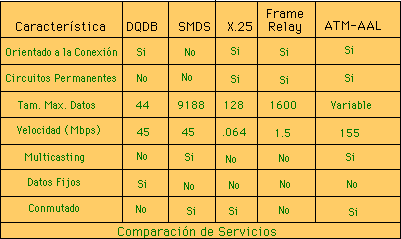
Algo novedoso de ATM es que se dice que es un modelo tridimensional, ya que cada capa antes vista tiene dos planos de soporte. El primer plano, conocido como de usuario, consiste de funciones de transporte de datos, control de flujo y corección de errores. El otro plano, conocido como control, se encarga del establecimeinto de conexiones y coordinación entre capas y subcapas del modelo. Para finalizar estos repasos de servicios, podemos consultar una tabla comparativa basada principalmente en [Tan96 pag. 66].
8. LOS NIVELES DEL MODELO OSI
Debido a la importancia histórica y a su
relevancia didáctica, el modelo de referencia OSI se utiliza para
describir otros modelos y arquitecturas de red. A pesar que se ha criticado
su estratificación de 7 capas como una forma de apego al modelo
que IBM propuso cuando era la compañia dominante, el modelo tiene
su lado bueno principalmente porque ayuda a ubicar de manera clara las
funciones, servicios y organización de la mayoría de las
arquitecturas de red existentes.
8.1 Fórmula de Nyquist
Dado que las comunicaciones modernas están basadas en señales digitales, y éstas tienen que viajar por algún medio de transporte, es importante saber cúanta información es posible transmitir en un medio físico. Recordemos que en un intervalo de tiempo, si incrementamos la frecuencia de una señal tambíen estamos decrementando su amplitud. Nyquist demostró que existe un límite para la cantidad de datos que podemos transmitir en un medio con un ancho de banda B. Por ejemplo, si el ancho de banda es 200 Hertz (200 pulsos por segundo), para una señal con dos niveles de señalización (por decir algo, 0 y 5 volts) la máxima cantidad de bits por segundo son 2B=400. Y en general, para una señal con M niveles de señalización la cantidad es:
Bits por segundo = 2Blog2M recordando que: logxY = ln Y/ln X
Ejemplo 2: Si tenemos un medio con tres niveles de señalización (M=3) y un ancho de banda de 2500 Hertz, la cantidad de bits máxima que se pueden transmitir son:
Bits por segundo = 2(2500)log2(3) = 5000(0.69) = 3450
Por otro lado, Shannon encontró que si el medio de transmisión tiene ruido, el cual se mide como relación señal a ruido S/N (S=señal, N=ruido) nombrada en decibeles, entonces la máxima cantidad de bits por segundo que se pueden transmitir sin importar cuántos niveles de señalización se empleen es:
Bits por segundo = Blog2( 1 + S/N) (F1)
Por ejemplo, para una línea telefónica a 3000 Hertz, la máxima cantidad de información que se puede transmitir tomando una relación señal a ruido típica de las líneas analógicas de 30 decibeles es:
S/N = 10 log10 (S/N dB) (Primera parte de la ley de Shannon-Hartley)
30 = 10 log10 (S/N dB) Despejando :
S/N dB= 10 ( 30 / 10 )
S/N dB= 1000 Sustituyendo en F1:
Bits por segundo = 3000 log2( 1 + 1000) = 3000 ( 9.9672) = 29901
Entonces, para una línea telefónica analógica típica, podemos transmitir hasta 29901 bits por segundo a lo máximo sin importar cúantos niveles de señalización usemos.
8.2 Medios de transmisión nivel físico
Cuando necesitamos decidir qué medio de transmisión es el adecuado para nuestras necesidades, debemos tomar en cuenta sus características para saber en qué medida resuelve nuestros problemas actuales y planear cambios en el futuro.
8.2.1 Par trenzado (UTP)
Se le conoce así al cable metálico (Unshielded Twisted Pair) cuyas características generales son:
8.2.2 Cable coaxial
Este tipo de cable está dejándose de usar para la transmisión de datos debido a las conexiones cuasimecánicas que necesita. El cable coaxial más usado para la transmisión de datos cuenta con las siguientes características:
El cable coaxial se clasifica como "baseband" si se utiliza para transmitir señales digitales y como "bradband" si se usa para señales analógicas.
8.2.3 Fibra óptica
Algunos autores comparan el crecimiento de la velocidad de los procesadores contra el de las comunicaciones por red, y se dice que las redes han crecido su velocidad en un factor de 100 mientras que el cómputo lo ha hecho en uno de 10, sin embargo, podría ser más significativo comparar la velocidad del "bus" de un nodo contra la velocidad de la red, y en ese rubro encontramos que el bus interno puede transferir hasta 80 Megabytes por segundo mientras que las redes más avanzadas hablas de 622 Megabits por segundo. Considerando lo anterior, todavía tenemos un déficit en la comunicación CPU-CPU de los nodos de una red, lo cual es una traba enorme, por ejemplo, en la construcción de sistemas distribuidos. La traba principal para lograr mayores velocidades en las redes es la incapacidad para convertir señales de luz a señales eléctricas, aunque se esperan velocidades de 1 Terabit por segundo en pocos años.
La fibra óptica puede ser de tipo multimodal o unimodal. La primera tiene la propiedad de reflejar internamente un haz de luz, rebotando en el interior de la fibra. La segunda tiene un diámetro interno menor de manera que la luz no puede rebotar y entonces la fibra actúa como una guia recta de la luz. Las fibras unimodales son más caras y pueden transmitir hasta varios Gigabits por segundo hasta por 30 Kilómetros, y por 100 kilómetros aunque a velocidades más bajas sin necesidad de repetidores. Conforme la luz viaja en la fibra su amplitud crece provocando distorsión. Se ha encontrado que si los pulsos de luz se envían con una forma relacionada recíprocamente al coseno hiperbólico la distorsión se cancela y los pulsos pueden viajar por miles de kilómetros. A este tipo de pulsos se les conoce como "solitons" y se estudia su aplicación en la práctica.

La ventaja de la fibra óptica sobre otros medios de transmisión es que no es susceptible de interferencias externas, no es fácil lograr intromisiones sin suspender el servicio, en un haz de fibras de una pulgada de diámetro pueden acomodarse más de cien fibras debidamente protegidas. Además de la cubierta de vidrio de diferente índice de refracción, los haces de fibra cuentan con una película de sustancia gelatinosa que además de absorber vibraciones contiene veneno para roedores. La desventaja de la fibra es que si llega a trozarse, se tiene que hacer un arreglo relativamente caro que puede ser un alineamiento mecánico fijo con pérdida del 10% de luz, pueden ajustárseles conectores y los conectores unirlos con una guía con pérdida del 10 al 20% de luz o pueden fundirse en un arreglo térmico con pérdida mínima. El otro problema ante daño físico es la identificación de los pares correctos. En el emisor se puede usar un diodo emisor de luz o un láser de semiconductor. En el destino puede estar un fotodiodo, cuya característica es que emite un pulso eléctrico cuando es impactado por la luz. Los fotodiodos responden hasta en un nanosegundo, lo cual limita la velocidad de la fibra a un gigabit por segundo.
8.3 Transmisión inalámbrica nivel físico
La transmisión inalámbrica se aplica en los usuarios móviles y cuando se necesita unir puntos separados por montañas u otros obstáculos del terreno. Algunos especialistas consideran que en el futuro los medios de transmisión serán fibra o inalámbrica. El principio básico de la transmisión inalá mbrica consiste en que si un electrón se mueve en el espacio, se generan ondas que viajan incluso en el vacío a la velocidad de la luz independientemente de su frecuencia. La distancia entre dos crestas de onda se le llama longitud de onda y se denota por el símbolo l. En la fibra o cobre la velocidad baja aproximadamente a 200,000 Km/s y depende un poco de la frecuencia. La relación entre la velocidad de la luz (c), la longitud de onda y la frecuencia (f) en el vacío es:
fl = c (Fórmula 1)
Como la velocidad de la luz es constante (hasta ahora), si conocemos f podemos obtener l y si conocemos l podemos obtener f. Por ejemplo, si la frecuencia en una fibra es de 622 MegaHertz, su longitud de onda es (300,000Km/s)/(622,000,000 Hertz) = 0.0005 Km = 0.5 Mts. En el espectro electromagnético podemos encontrar varios medios para transmitir información modulando la amplitud, la frecuencia o la fase de las ondas.
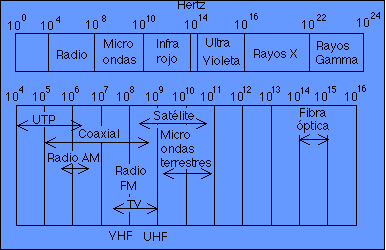
Como sabemos, los rayos de más alta frecuencia y que podrían llevar más información son los X, Gamma y Ultravioleta, pero no se usan porque son perjudiciales para los humanos y porque son difíciles de modular, por eso se usan frecuencias más bajas. La cantidad de información que una onda puede llevar está relacionada con el ancho de banda. En altas frecuencias es posible codificar hasta 40 bits por cada Hertz, así que un cable a 500 Mhz podría llevar 4 Gigabits/s. Si derivamos con respecto a lambda en la fórmula 1, tenemos:
df/ d l = (- c )/ l 2 y con diferencias finitas obtenemos:
D f = ( c Dl)/(l 2 )
lo cual significa que la frecuencia crece de acuerdo
al crecimiento de la longitud de onda, por eso la mayoría de los
países quieren apropiarse de las ondas con banda mas amplia.
8.3.1 Transmisión por radio
Como ya vimos, una carga eléctrica en movimiento genera un campo magnético y un campo eléctrico. Si en una antena (que pueden ser un par de cables paralelos) se producen corrientes eléctricas que oscilan de t1 en positivo a t2 en negativo, se producen campos eléctricos y magnéticos que se propagan, en teoría, hasta el inifinito. El campo magnético rodea a la antena como una piedra arrojada al agua y el campo eléctrico es perpendicular.
A la unión de los dos campos constituyen las ondas electromagnéticas y su velocidad en el aire es ligeramente inferior a 300,000 Km./s. Cuado estas ondas llegan a otro par de cables paralelos unidos a un circuito eléctrico completo, producirá una fuerza electromotriz (fem) a la vez que obligan a los electrones a moverse generando una corriente eléctrica muy pequeña, pero suficiente para que los circuitos electrónicos la transformen en una señal de alta energía que representa la transmisión radiofónica. Las frecuencia usadas para la transmisión de radio van más allá de los 100 Kilociclos o Kilohertz. Observe la carátula de su receptor de radio para ver los límites usados en la radio comercial. Las ondas de radio pierden potencial inversamente proporcional al cubo de la distancia recorrida en el aire. Pueden pasar obtáculos más fácilmente mientras menor es su frecuencia, a mayor frecuencia viajan cada vez más en línea recta y son absorbidas por la lluvia o el agua. En todas las frecuencias sufren interferencia por campos eléctricos o magnéticos. Las ondas de radio de muy baja, baja y mediana frecuencia (10 4 -10 7 ) viajan siguiendo la curvatura terrestre, mientras que las de alta frecuencia (10 7 -10 8 Hz) pueden enviarse hacia la ionósfera en donde rebotan como si hubiera una repetidora (sin regenerar la señal) y tomar el rebote en una retransmmisora. Las frecuencias altas y muy altas son usadas para transmisiones militares.

8.3.2 Transmisión por microondas
Las ondas de frecuencias mayores a 100 Mhz viajan
en línea recta y necesitan alinearse el transmisor y el receptor.
Este tipo de señales son absorbidas por la lluvia y la tierra, por
lo cual necesitan repetidoras terrestres o satélites. Para unas
torres de 100 Mts. de altura la distancia de separación es 80 Km.
La mayor parte del espectro arriba de los 100
Mhz. está estandarizado por la ITU-R, aunque hay algunas bandas
que no necesitan licencia. Las bandas de 2.4 a 2.484 Ghz se usa para transmisiones
médicas, científicas e industriales. Las bandas de 902 a
928 Mhz y 5.725 a 5.850 Ghz se usan para teléfonos inalámbricos
y controles remotos.
Entre más alta la frecuencia, más
cara es la electrónica para manejarla y más interferencia
se puede tener de hornos de microondas y radares. En comparación
con la fibra óptica, las microondas son más baratas porque
no necesitan un cable.
8.3.4 Transmisión infraroja
Los controles remotos de nuestros televisores trabajan con una pequeña luz infraroja que es muy útil en las transmisiones en distancias cortas, la desventaja es que no debe haber ningún obstáculo entre el emisor y el receptor. Mientras las frecuencias de radio se acercan a las frecuencias de la luz visible se comportan menos como radio y más como luz. La luz infraroja no se puede usar en exteriores porque el sol las anula.
8.3.5 Transmisión láser
Para resolver el problema de que la brillantez
del sol anula la lus infraroja, se usan rayos láser en pequeñas
distancias. El rayo láser es una luz muy potente y coherente (que
no se dispersa fácilmente con la distancia). El rayo láser
es unidireccional y para hacer LANs se necesitan dos rayos por cada nodo.
8.4 Transmisión vía satélite nivel físico
Un satélite artificial puede ubicarse a 36 mil Km. en órbita sobre la tierra y a esa distancia tiene la propiedad de mantenerse sobre una misma área, lo cual es muy útil para enviarle señales. Con la tecnología actual, se pueden colocar satélites cada dos grados, lo cual permite poner sobre una misma línea hasta 180 satélites alrededor de la tierra. Se pueden poner dos o más satélites más cerca de dos grados si trabajan en fecuencias diferentes. Las partes más importantes del satélite son sus "transponders", que se encargan de recibir la señal que viene de la tierra y de repetir la señal de regreso con una frecuencia diferente y sobre un área preprogramada. Se han destinado ciertas frecuencias para las transmisiones comerciales. La banda C fue la primera y ya está saturada, la banda Ku no está saturada pero por su frecuencia es fácilmente interferida por la lluvia, por lo cual se instalan estaciones terrestres extras para darle la vuelta a las tormentas. La banda Ka es la más cara y menos usada y también se perjudica con la lluvia. Existen otras bandas pero son para uso militar.
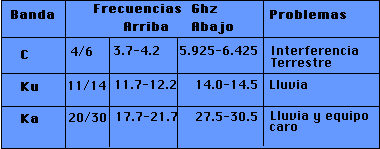
Una desventaja de los satélites es el retraso inherente al viaje de ida y vuelta, el cual puede variar de 250 a 540 milisegundos, y este valor no se puede evitar y afecta, sobre todo, a la puesta a punto inicial de una conexión, ya que una vez establecida el flujo de datos se considera secuencial.

8.5 Aspectos del nivel de ligado de datos
La capa de enlace de datos realiza las tareas de agrupar los bits provenientes de la capa física y los agrupa para formar marcos (frames), así como tareas de control de errores y control de flujo. Los servicios que la capa de enlace ofrece pueden ser de tres tipos: no orientados a la conexión, no orientados a la conexión sin confirmación y orientados a la conexión con confirmación.

La mayoría de las arquitecturas de red ofrecen un servicio no orientado a la conexión y sin confirmación en la capa de enlace de datos o correspondiente, ya que la capa de red puede hacerse cargo de esa tarea. La confirmación de recepción de un marco le sirve al emisor para saber que el marco llegó a su destino a la capa correspondiente de enlace de datos, lo cual no debe confundirse con que llegó íntegro a la aplicación. Como dijimos, una tarea llevada a cabo en esta capa es la de agrupar los bit que vienen de la capa física y crear marcos. La longitud de los marcos puede ser fija o variable, y puede ser un múltiplo en bits del tamaño en bits del código usado (ascii, ebcdic, etc.). la tarea de enmarcado se puede efectuar por varios métodos que se describen a continuación.

Un problema que puede suceder tanto en este método como en el anterior es los datos a enviar contengan precisamente o por coincidencia la cadena de control (o caracter de inicio o fin). La solución es muy simple y consiste en modificar la cadena de control que viene como dato insertándole enmedio una cadena de control. Por ejemplo, si los datos son la cadena:
0011001110100001001100
el marco resultante sería:
1000010011001110100100001001001100100001
y como en el destino estos bits son eliminados, la cadena de datos entregada a la capa de red es:
0011001110100001001100
8.5.1 Detección y corrección de errores
Otra tarea importantísima de la capa de enlace (y de las demás capas superiores) es la de detectar, y si se desea, corregir errores ya que el nivel físico tradicionalmente no está libre de errores por ruido termal, interferencias elctromagnéticas, etc.

Una vez que la capa de enlace ya sabe como identificar
el comienzo y fin de un marco, se puede dar a la tarea de verificar si
están correctos. Se pueden hacer dos cosas: simplemente detectar
que hubo un error y pedir la retransmisión del marco o mensaje (lo
cual no es factible en líneas unidireccionales) o bien corregir
los bits dañados.
Para detectar que hubo un error, al enviarse un
marco se guarda en una tabla cuándo se envió y se le asocia
un tiempo para recibir su confirmación. Si no se recibe la confirmación
por parte del receptor, se re-envía el marco. El problema que puede
surgir es que si se perdió la confirmación, el receptor puede
tener marcos duplicados, lo cual se soluciona al asignar un número
de secuencia a cada marco, para descartar los duplicados y re-enviar su
confirmación. Otra forma de detectar un error (que ya no fue la
pérdida del marco, sino la corrupción de su contenido), es
insertar un código de chequeo, y para esta labor se utilizan códigos
basados en el concepto de "distancia de Hamming". La distancia de Hamming
para un código cualquiera se define como el número de bits
diferentes al hacer un XOR entre todos sus símbolos. Por ejemplo,
si tenemos un código con los símbolos A,B,C; donde A = 11000,
B=00011, C=01101, tenemos:
|
A xor B 11000 |
A xor C 11000 |
B xor C 00011 |
|
00011 |
01101 |
01101 |
|
4 bits |
3 bits |
3 bits |
Distancia de Hamming = mínimo(4,3,3) = 3 bits.
Si los símbolos de un código difieren a lo menos en X bits, es posible saber que ocurrieron X-1 errores ya que al variar un símbolo válido (dañarlo) en X-1 bits es imposible obtener otro símbolo válido. Si los símbolos de un código difieren a lo menos en 2X+1 bits, al variar X bits (dañar X bits) obtenemos un nuevo símbolo que se parecerá más en un bit a un código válido que a otro código válido y por lo tanto podemos decir que el símbolo dañado en realidad es el más parecido realizando así su corrección. Por otro lado, si la longitud de los datos es M bits y consideramos que los bits que producen la distancia de Hamming es de R bits, entonces tenemos que la longitud de la cadena sin incluir el inicio y fin de marco es N con N=(M+R). Compruebe que para corregir un error en una cadena se debe cumplir que (M+R) < 2 R. Por ejemplo, si destinamos 3 bits al chequeo, (M+3) < 8, entonces M < 5, lo que significa que puedo tener un código de 32 símbolos con capacidad de corregir errores de un bit. Esta fórmula sirve para establecer el tamaño de una cadena de transmisión mínima con corrección de errores.
Para el diseño estándard de protocolos, se han especificado algunas cadenas de chequeo bien conocidas llamadas CRC-12, CRC-16 y CRC-CCITT con R=12,16 y 16 bits respectivamente. Estas cadenas se interpretan como polinomios de la manera que sigue.
CRC-12 = 1100000001111 = X^12 + X^11 + X^3 + X^2 + X + 1.
CRC-16 = 11000000000000101 = X^16 + X^15 + X^2 + 1
CRC-CCITT = 10001000000100001 = X^16 + X^12 + X^5 + 1
Observemos que la posición del bit con un uno representa la potencia del polinomio. Cada uno de estos polinomios se conocen como "generador polinomial" y las siglas CRC significan "Cyclic Redundancy Code".
Los tres pasos para detectar errores con estos polinomios son:
El efecto del algoritmo anterior es simple, si hacemos lo mismo con un número decimal conocido. Supongamos que CRC=3 y P = 25. Al dividir 25 entre 3 nos da un residuo K=1. Entonces lo que enviamos es una cadena compuesta de las partes 25-1= (24). Observemos que no se transmite el 24, sino una cadena 25-1. En el destino, se hace la división (binaria) de la cadena compuesta (25-1)/3 = 8 y el residuo es cero, lo cual significa que la cadena original es correcta y son los primeros M bits.
8.5.1.1 Control de flujo
El control de flujo es otra tarea realizada por vez primera en la capa de enlace de datos y que también puede estar presente en las capas superiores. El control de flujo resuelve el problema de que un nodo envía datos más rápido de lo que el receptor los puede procesar o viceversa. En la sección 8.7.1.2 revisaremos más a detalle las técnicas para realizar el control de flujo, aunque podemos adelantar diciendo que la solución a este problema se entiende haciendo una analogía del emisor con un grifo de agua y el receptor con un recipiente. Si el emisor es más rápido que el receptor, tenemos que cerrarle un poco a la llave (decrementar el número de marcos o paquetes por segundo enviados por segundo). Por otro lado, si el receptor es más rápido (la cubeta es muy grande), le abrimos más a la llave.

8.5.2 Protocolos del nivel de enlace de datos
Un problema importante en el diseño del protocolo de enlace de datos es la manera en como se van a enviar datos y a recibir las confirmaciones. Una solución sería tener dos canales unidireccionales, uno para enviar datos y otro para recibir las confirmaciones, pero es claro que esta solución es ineficiente porque desperdiciaríamos mucho el canal de confirmaciones. Para optimizar un poco (o mucho) el método de confirmación, el receptor puede aprovechar que la capa de red envía paquetes de respuesta al emisor y le anexa a dichos paquetes la confirmación de los paquetes recibidos. Esta forma de confirmar se le conoce como "piggybacking". El cuidado que se debe tener con esta técnica es que el receptor no espere demasiado a que exista un paquete de respuesta para enviar su confirmación, si el paquete de respuesta no llega en un tiempo alfa predeterminado, debe enviar la confirmación en un paquete por separado. La confirmación de la recepción de marcos (o paquetes) se puede hacer de manera síncrona si el emisor, para transmitir un nuevo paquete X espera la confirmación del paquete X-1. Si el protocolo contempla enviar Y paquetes de golpe, y para enviar un paquete más requiere de la confirmación de un paquete anterior cualquiera que sea su número de secuencia, entonces estamos ante un protocolo de ventana deslizante, del cual hablaremos más extensamente en la sección 8.7.1.2.
8.5.2.1 Protocolo de enlace de datos PPP
Aunque existen muchos protolos comerciales o aceptados en todo el mundo, tales como SDLC (Synchronous Data Link Control de SNA IBM), y sus derivados ADCCP (Advanced data Communication Control Procedure de ANSI), HDLC (High-level Data Link Control de ISO), LAP (Link Access Procedure de X.25), revisaremos el protocolo PPP (Point to Point Protocol) porque está en auge al igual que el uso de Internet. El protocolo PPP esta descrito en los RFC 1661 a 1663. Es el estándard usado en Internet para conexiones de un nodo aislado (por ejemplo una computadora en el hogar) hacia un servidor en Internet (por ejemplo, un servidor de terminales de una LAN en Internet). PPP provee los siguientes servicios:
Una sesión típica con el protocolo PPP sería que un ama de casa inicia una llamada a su proveedor de Internet por medio de un módem. El módem establece un enlace físico con el enrutador del proveedor de Internet y el protocolo LCP se encarga de negociar cómo se va a trabajar a nivel de enlace de datos. Después una serie de paquetes de tipo NCP negocían con la capa de red la obtención de una dirección IP para tener la suite completa de TCP/IP. En este momento podemos decir que el ama de casa forma parte de la red de su proveedor de Internet y cuando termine su sesión de trabajo, NCP se encargará de negociar con la capa de red (IP) la terminación de la conexión, luego LCP cerrará el enlace y el módem colgará la llamada.
Los campos de un marco de PPP son:
8.5.3 Estándares para LANS y MANS
La reservación de frecuencias en la transmisión de ondas, derechos de paso para cableado y todo lo relacionado con la infraestructura de las redes mundiales no puede hacerse a la ligera porque habría un caos. Se han hecho muchos esfuerzos para publicar estándares a nivel mundial que reglamenten esta actividad. La Organización de la Naciones Unidas ha logrado formar un comité que coordina los esfuerzos de los diferentes institutos iternacionales que producen estándares. El comité funciona como una agencia denominada ITU (International Telecommunications Union) y sus tres sectores principales son:
ITU-T ha logrado cierta claridad en nombrar equipos
de trabajo que trabajan coordinadamente en cada país revisando y
proponiendo nuevos estándares o mejoras a estándares viejos.
Las dos ramas mundiales más importantes
son los esfuerzos de estandarización de ITU-T y de la comunidad
de Internet. La comunidad de Internet tiene dos comités que son
el IETF (Internet Engineering Task Force) y el IRTF (Internet Research
Task Force) coordinados bajo el IAB (Internet Activities Board).
El proceso para lograr estándares se parece
mucho al proceso de ISO: Los estándares propuestos se envian y se
publican como un RFC (Request for Comments), si el estándard propuesto
ahí es implantado y probado durante cuatro mese, avanza al estado
de estándard en sucio (Draft Standard) y si el IAB evalúa
que el estándard sirve y es ampliamente aceptado entonces se le
da el grado de Estándard de Internet.
8.5.4 Dispositivos físicos
En el argot de las redes de datos se manejan un sin fin de términos que para el profano resultan desconcertantes, y para el purista del idioma resultan una aberración. Sin embargo tenemos que conocerlas y usarlas porque es uno de los objetivos de este curso.
8.6 ASPECTOS DEL NIVEL DE RED
Se puede decir que la capa de red es la última de bajo nivel que está relacionada con la transmisión de datos punto a punto. En el nivel de red interactuan varios dispositivos de red que se encargan de dirigir los paquetes en la subred hasta su destino final.
8.6.1 Servicios
La capa de red ofrece servicios a la de transporte por medio de la interfase red/transportey cumple con estos objetivos:
La industria telefónica propone que el servicio ofrecido a la capa de transporte sea de tipo orientada a la conexión y la comunidad de Internet propone que sea de tipo no orientada a la conexión, cada facción apoyada por su propia experiencia. Lo importante de esto reside en que dependiendo de la elección se tendrá el control de flujo y chequeo de errores en la capa de red o en la de transporte, lo cual se traduce en que la parte dura la hará el proveedor de la subred o el usuario en sus aplicaciones. Si combinamos un servicio orientado a la conexión en el nivel de transporte con una subred no orientada a la conexión, tendremos el chequeo de errores y control de flujo en la capa de transporte y una capa de red bastante sencilla y, lógicamente, eficiente. La comunidad de Internet propone la suite de protocolos TCP/IP para ofrecer servicios orientados a la conexión y confiables (TCP), así como no orientados a la conexión y no confiables (UDP), mientras que la industria telefónica ofrece ATM con servicios orientados a la conexión y confiables. La combinación ineficiente resulta cuando la comunidad de Internet utiliza TCP/IP sobre una subred con ATM porque se duplica el control de flujo y chequeo de errores.
8.6.2 Circuitos virtuales y subredes
Un circuito virtual es un enlace que se establece entre dos entes de una subred. Está asociado a los servicios orientados a la conexión y su analogía es un cable que se tiende entre los dos entes. En la vida real, este circuito se establece como una ruta negociada entre los dispositivos de la subred y permanece mientras el par de entes no negocien su terminación. Por otro lado, si los paquetes de un enlace viajan por rutas distintas se establece un servicio no orientado a la conexión y a los paquetes se les denomina "datagramas" (datagrama por su analogía a telegrama).
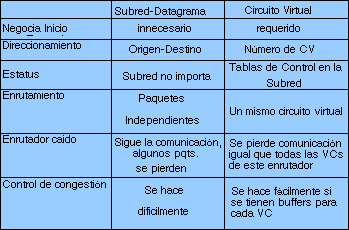
8.6.3 Ruteo
Como djimimos, la labor principal de la capa de red es dirigir por el mejor camino a los paquetes desde un orígen a su destino. La decisión de cuál es el mejor camino puede basarse en varios factores como son:
Dependiendo del usuario, algunos pueden preferir dar pocos saltos, mientras otros prefieren líneas con pocos errores, otros desean líneas baratas, etc. Los aparatos que deciden qué rutas van a seguir los paquetes o datagramas se denominan "enrutadores". Cuando son encendidos, envían mensajes especiales (generalmente de tipo broadcast) bajo un protocolo de enrutamiento para determinar qué caminos tiene disponibles localmente y cuáles tienen los enrutadores vecinos. También pueden intercambiar las rutas conocidas de vecinos con otros vecinos, creando así tablas de enrutamiento dinámicas. El administrador de la red también puede insertar rutas a mano creando rutas estáticas. Los algoritmos de ruteo entonces pueden ser dinámicos o estáticos. Entre los algoritmos estáticos tenemos:
Para comprender mejor los algoritmos y protocolos de enrutamiento dinámicos, necesitamos comprender dos conceptos que son:
Regresando a los algoritmos de ruteo, en el tipo de los algoritmos dinámicos tenemos:
1. Descubrir los vecinos y registrar sus direcciones de red.
2. Medir el precio para llegar a cada enrutador vecino.
3. Construir un mensaje que contenga todo lo aprendido.
4. Enviar el paquete de conocimiento a los enrutadores vecinos.
5. Calcular la ruta más corta hacia cada enrutador alcanzable.
1. Se puede expandir el mensaje por el árbol mínimo de expansión (obtención difícil)
2. Se puede expandir por inundación (requiere mecanismo de paro)
3. El mensaje original puede contener una lista de destinos múltiples (preferible)
4. El mensaje se puede expandir por un árbol de sendero inverso (preferible)
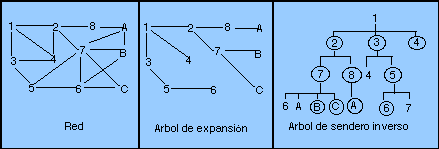
8.6.4 Congestionamiento de la red
El congestionamiento se refiere a que la capacidad de la subred en cuanto a almacenar datos que están pendientes de ser entregados excede a los recursos disponibles tales como memoria para colas, el ancho de banda de los enlaces, el número de enlaces y otros. Los datos pendientes se pueden acumular debido a que la cantidad de datos que los emisores intentan enviar excede a la capacidad de la subred en cuanto al ancho de banda, o bien que la caida de enlaces o un mal control de flujo provocan la congestión. Recordemos que que el control de flujo tiene que ver con emisores y destinatarios que trabajan a velocidades diferentes y que requieren cierta sincronización en cuanto a la velocidad en que procesan datos en la red. El control de congetionamiento de la red tiene dos vertientes de solución: estáticas y dinámicas. Las estáticas establecen que el buen diseño de la red y las dinámicas en una retroalimentación de la subred. Para la solución dinámica, se realizan tres pasos en general que son:
1. Monitoreo de la red: Si se incrementa el valor del número de paquetes descartados porque ya no hay buffers de almacenamiento, el tamaño de las colas de almacenamiento, el número de paquetes retransmitidos que no son por colisiones, el tiempo promedio de entrega, entonces hablamos de congestionamiento.
2. Enviar la información de congestión al lugar indicado: Cada enrutador puede asociar a los paquetes de enrutamiento o al procolo del nivel de red algunos bits que indiquen el estado del monitoreo, para que sus vecinos modifiquen el enrutado de pauqtes y se eviten congestiones de manera dinámica.
3. Ajustar la operación del sistema apropiado: Una vez que un elemento de la subred o un emisor o receptor recibe información de monitoreo indicando que hay un problema de congestión, éste debe tomar alguna acción para detener o disminuir la congestión, tal como enviar sus paquetes por una ruta alterna o tomar una acción de control de flujo (disminuir el número de paquetes por segundo enviados).
8.6.4.1 Tabla de políticas generales en la congestión
El primer paso para lidiar con la congestión de tráfico consiste en tratar de evitarla. Se pueden realizar algunas acciones en los niveles de enlace de datos, red y transporte como se indica en la tabla siguiente.
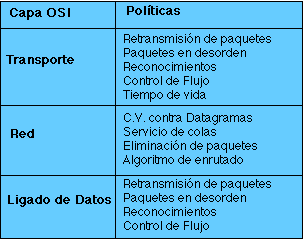
8.6.5 Firewalls
La inclusión de redes privadas dentro de Internet y la necesidad de mantenerlas protegidas contra ataques al mismo tiempo ha dado cabida a la instalación de mecanismos de protección para incrementar la seguridad en dichas redes. La idea general de incluir una red privada en Internet es la de tener acceso a las herramientas e información de esta red de redes, a la vez que aprovechar su alcance para llegar a miembros alejados de una misma corporación. Para lograr un acceso más o menos amigable a Internet sin perder la seguridad interna se ha acuñado el concepto de Firewall (muro de fuego), cuya función principal es la de levantar un obstáculo para la transmisión y recepción de información de y hacia la red privada o protegida. El obstáculo (firewall) sólo puede ser vencido conociendo una o varias claves de acceso pre-establecidas por el administrador del firewall. Las soluciones firewall generalmente consisten de una parte de software y otra de hardware. El hardware puede ser desde una computadora personal con funciones de pasarela (gateway) en hardware o software. La parte de software consiste de programas que filtran los paquetes dejando pasar sólo aquellos que cumplen las políticas de seguridad de la red protegida, o bien de programas que convierten una petición de servicio hacia un formato de seguridad.
Entre los servicios más comunes de un firewall podemos encontrar:
8.6.6 ATM
La capa llamada ATM del modelo ATM es lo más cercano a las características de la capa de red del modelo OSI, aunque muchos expertos consideran que la capa ATM es la de ligado de datos. Aceptemos la controversia y procedamos a ver esta capa como la de red. La capa ATM es orientada a la conexión, y es novedosa porque no incluye el uso de reconocimientos porque fue diseñada para trabajar con medios físicos de transporte libres de errores como la fibra óptica. Además, ATM en general se usa para enviar información en tiempo real, lo cual hace peor el re-enviar una celda dañada que ignorarla. ATM se basa en la creación de circuitos virtuales unidireccionables, de manera que para crear un canal virtual full duplex crea dos circuitos con el mismo identificador lógico, y en dichos canales las celdas siempre se envían y llegan en orden. Además, los canales virtuales pueden agruparse y tratarse como una unidad llamada sendero virtual.
8.6.6.1 Formato de las celdas de ATM
En la capa de ATM se localizan dos interfases: la UNI (User Network Interface) y la NNI (Network to Network Interface). La primera define el límite entre un nodo y la red de ATM y la segunda se refiere a la relación entre dos conmutadores (switches) de ATM. En ambos casos las celdas consisten en encabezados de 5 octetos de longitud y una sección de datos (payload) de 48 octetos
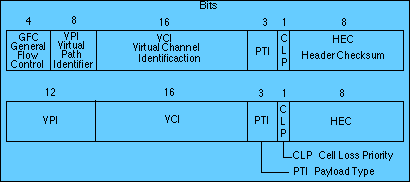
8.6.6.2 Servicios de ATM
Para la versión 4.0 de ATM la comunidad se dio cuenta de qué era lo que el estándard podía transmitir y qué era lo que el público deseaba transmitir, por lo cual se modificó el estándard para satisfacer mejor a los usuarios y se escogieron los servicios más deseables para que los fabricantes produjeran dispositivos más ad hoc.

CBR es útil para ofrecer los servicios que típicamente resuelve el sistema telefónico, aunque no hay control de errores, ni congestionamiento ni ningún otro procesamiento extra. RT-VBR garantiza que la aplicación obtendrá el ancho de banda requerido y es útil en servicios de tiempo real como las videoconferencias y el despliegue de presentaciones tipo filme. NRT-VBR es igual que el anterior, excepto que el protocolo puede tener un retraso en la entrega tal como en el servicio de correo electrónico. ABR está enfocado a ofrecer un ancho de banda base y si la aplicación requiere más entonces hará su mejor esfuerzo para incrementarla. UBR no promete ningún ancho de banda base ni control de flujo ni chequeo de errores, lo cual es útil para enviar paquetes IP y no incrementar la sobrecarga en el nivel de transporte. Si la red está congestionada, los paquetes son descartados sin avisar, pero si hay ancho de banda sobrante, se entregan la mayor cantidad de paquetes posibles.
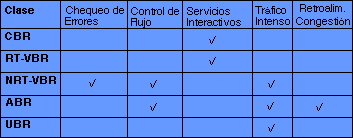
8.6.6.3 Calidad del servicio en ATM
Para efectos de establecer una especie de control de calidad en los servicios (CBR, ABR, UBR, etc.), se han definido una serie de parámetros que el cliente y el proveedor pueden negociar de acuerdo a la tabla siguiente.

La calidad del servicio se define con parámetros de envío de celdas por un lado y en la entrega de las mismas por el otro. Por ejemplo, el cliente podría negociar que el CMR sea a lo más 1 celda por segundo, es decir, que solamente se entregue una celda en un destino equivocado por segundo, tomando en cuenta que tal vez el PCR sea 150,000 celdas por segundo.
8.6.7 El protocolo IP
Internet como ya hemos visto es una red de redes y se expande a nivel mundial, su protocolo base es TCP/IP, y fue diseñado desde el principio para trabajar entre redes. La manera general en que trabaja TCP/IP es que la aplicación le entrega una cadena de datos al protocolo de transporte ( TCP o UDP ) el cual se encarga de contactar a la capa de red (IP) y entregarle datagramas que pueden ser hasta de 65 Kb de longitud (aunque la mayoría de las tarjetas de red manejas una longitud máxima de 1500 bytes denominada Maximum Transmission Unit). La capa de red IP transmite los datagramas, tal vez divididos en unidades más pequeñas (fragmentos) hasta el destino, haciendo su mejor esfuerzo porque los paquetes lleguen a su destino. En el destino la capa IP ensambla los fragmentos y entrega los datagramas a la capa de transporte quien a su vez se los entrega a la aplicación.
Un paquete de IP tiene una estructura compuesta de una parte de encabezado y otra de datos. El encabezado consta de 20 octetos fijos y de una parte de opciones cuyo tamaño es variable (de cero o más octetos).
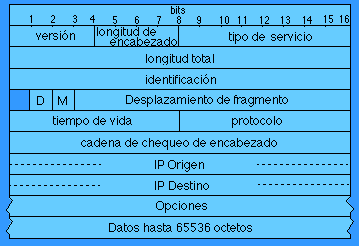
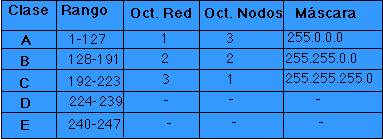
Algunos números de IP son especiales. Aquellos Ips cuyo número de red sean puros ceros indican que el destino es la red local. Si el destino consiste de un número con puros unos, quiere decir que el destino son todos los nodos de una red. Si el destino comienza con el número 127.x.y.z, los paquetes no son puestos en la red sino que se procesan en el mismo nodo como si fueran paquetes que llegaron y su propósito es hacer pruebas.
8.6.8 Algunas notas acerca de IP Versión 6
El crecimiento de Internet tan enorme aunado al desperdicio provocado por las división en sólo 5 clases ha redundado en que el número de direcciones IP disponibles actualmente se acerque a cero. Otro problema importante es el surgimiento de protocolos nuevos ( como ATM, Frame Relay, etc.) donde no es tan natural la unión con redes típicas (legacy networks). Para solucionar los dos problemas anteriores y otros más, el Internet Engineering Task Force (IETF), que es un organismo que trabaja para que Internet sea más eficiente, convocó a todas las empresas e instituciones a proponer soluciones en 1990, y para diciembre de 1992 se tenían ya siete y después de discutirlas se llegó a proponer un nuevo estándard llamado Simple Internet Protocol Plus o IPv6. Se diseñó tomando en cuenta toda la experiencia reunida en IP y se plantearon los siguientes objetivos a resolver:
IPv6 no es compatible con la versión 4 de uso en 1997, aunque lo es con TCP, UDP, ICMP, OSPF, IGMP, BGP y DNS.
Lo que tenemos que esperar en el corto plazo es la forma de migrar nuestras redes actuales hacia nuevos esquemas de direccionamiento, nuevas tarjetas de red y el surgimiento de nuevas versiones para programar en red y aplicaciones nativas sobre IPv6.
8.7 ASPECTOS DEL NIVEL DE TRANSPORTE
En nuestra sección de programación en red utilizamos un medio de transporte de la suite de protocolos de TCP/IP. Como ya experimentamos, nuestra aplicación usó directamente la capa de transporte, ya que en la mayoría de los protocolos las capas de sesión y presentación son inexistentes.
8.7.1 Servicios
Recordemos que el propósito de la capa de transporte es ofrecer servicios eficientes, confiables (si así lo pide el cliente) y expedito al nivel superior que casi siempre es la aplicación misma (nuestros programas en sockets cliente-servidor) o bien un servicio confiable (como el NFS, NetNews, FTP, Telnet y muchos más). La capa de transporte ofrece servicios orientados y no orientados a la conexión, y pueden ser confiables o no confiables, y esto al parecer es lo mismo que ofrece la capa de red, excepto que el control de la capa de transporte es llevada a cabo en un nodo (computadora) particular y no en la subred. De tal manera podemos decir que de la capa de red para abajo tenemos una capa gigante llamada Proveedora de Servicio de Transporte, mientras que las superiores se pueden llamar Usuarios del Servicio de Transporte. También podemos decir que la capa de transporte es el límite entre nuestro proveedor de servicio de red física (subred) y el usuario final. Aprovechando que la capa de transporte es el colchón entre la subred y la aplicación, la podemos ver como la capa que subsana las posibles deficiencias que la subred tiene para ofrecer un servicio que satisfaga a nuestras aplicaciones. Y la satisfacción va de la mano con la calidad, la cual se puede especificar en términos de los siguientes conceptos.
La capa de transporte en el emisor, a través de la de red, ejecuta un proceso de estira y afloja con su contraparte en el destino acordando los valores de los parámetros de calidad de servicio, lo cual se llama negociación de opciones.
8.7.1.1 Primitivas de la capa de transporte
La capa de transporte cuenta con una serie de primitivas que permiten crear aplicaciones. En nuestros programas de sockets ya experimentamos primitivas reales de la capa de transporte de TCP/IP.

Si revisamos nuestros programas del Apéndice A, nos daremos cuenta que siempre hubo una secuencia de operaciones con las primitivas que permitieron establecer la conexión, que båsicamente componen una negociación para crear una enlace "orientado a la conexión".
8.7.1.2 Control de flujo en la capa de transporte
Ya vimos que en la capa de enlace de datos se lleva a cabo en algunos modelos (o en la capa correspondiente) el control de flujo. El por qué se hace control de flujo en esta capa se explica porque si se le deja esta tarea únicamente a la capa de enlace, entonces es factible que un emisor más veloz que un receptor lento provoque que el receptor descarte paquetes porque no puede atenderlos, lo cual ya no lo va a saber el emisor porque la subred confirma que los paquetes fueron recibidos. El control de flujo está basado en el uso de buffers en el emisor o receptor (o ambos) para almacenar todo aquél tráfico que excede la capacidad de procesamiento. Se recomienda que si la subred ofrece un servicio no confiable, el emisor tenga buffers con capacidad mayor o igual a R*C ( R por C), donde R es el tiempo de retraso promedio de entrega en la subred y C es la capacidad de transferencia de la subred. Por ejemplo, si la subred trabaja a C=10 Mbits/segundo y el retraso es 100 milisegundos (un retraso típico en una red nacional), entonces el buffer será mayor o igual a:
Buffer = .1 segundo * 10 Megabits/segundo = 1 Megabits = 125 Kilobytes
El manejo de este buffer se hace como de una ventana deslizante. La idea es enviar hasta C*R bits (en paquetes, o frames según sea la capa) y esperar a que se confirme la llegada de algunos de los paquetes enviados. Suponiendo que se confirmaron P paquetes, la ventana se deslizará hacia adelante P posiciones (que pueden ser de tamaño fijo o variable). Esto permite que se aproveche mejor la capacidad de la subred en lugar de estar enviando un paquete a la vez y esperar su confirmación. Además, si la subred ofrece servicios no orientados a la conexión, los paquetes pueden viajar cada uno por rutas diferentes y ser entregados en orden después
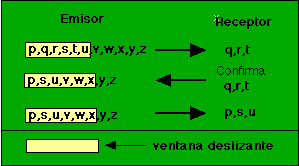
8.7.2 Direccionamiento
Otra características de la capa de transporte es que se requiere algún modo de direccionar o identificar de manera única cada conexión (el par de nodos interlocutores) o los paquetes que forman parte de una misma transmisión. En TCP/IP es una dirección IP y un número de puerto por cada nodo, en ATM es una par AAL-SAPs, y en general le llamaremos TSAP o PAST (Transport Service Access Point o Punto de Acceso al Servicio de Transporte). Los mismos puntos en la capa de red se llaman NSAP o PASR (Network Service Access Point o Punto de Acceso al Servicio de Red). Los paquetes de control de flujo, de retransmisión de paquetes, etc. que intercambian dos entidades de la capa de transporte se llaman TPDU o UDPT (Transport Protocol Data Unit o Unidades de Datos del Protocolo de Transporte). Son paquetes especiales en cuanto que no tienen ningún significado para las capas física, de enlace, de red, de sesión, de presentación ni para la aplicación, solamente le importan a la capa de transporte porque con ellos van a efectuar las operaciones pertinentes a esta capa del modelo. En nuestros programas de sockets, aprendimos que el direccionamiento de la capa de transporte (TCP) se especifica por un socket que consiste de una dirección IP y de un número de puerto que en nuestro caso fue el 50,000. En la comunidad de Internet, existen puertos que ya están reservados para ciertos servicios y hay otros puertos que se pueden usar a discreción por el programador de aplicaciones de red. Por ejemplo, el servicio TELNET se ofrece en el puerto 23, FTP en el 20 y 21, NetNews en el 119, SMTP en el 25, WWW en el 80, etc. Por otro lado, es muy común que al programar en red se utilicen, en lugar del IP, el nombre del nodo al cual se desea conectarse, lo cual requiere que exista un mecanismo de resolución que nos entregue la dirección IP para el nombre especificado. Esa resolución la realiza el Servicio de Nombres de Dominios (DNS Domain Name Service), el cual revisaremos en la sección 8.8.2. Para que quede una idea clara de las necesidades de direccionamiento único en la capa de transporte, observer en programa de sockets el procedimiento marca_numero( ), ahí observamos que se nos provee el nombre del nodo pero no su dirección IP, la cual resolvemos usando la función gethostbyname( ):
/* verificamos nombre */
if ((hp= gethostbyname(hostname)) == NULL) {
errno= ECONNREFUSED; /* y dirección */
return(-1); /* error, salimos */
}
Con la llamada anterior logramos construir el socket que necesita de la dirección IP (que es única a nivel mundial para cada nodo) y el puerto ya lo tenemos (que especifica un servicio único en ese nodo) y entonces tenemos un socket único a nivel mundial.
8.7.3 Protocolo TCP
El protocolo de control de transmisión (TCP en Inglés) fue diseñado para trabajar una capa de red no confiable, lo cual en un futuro, cuando se cuente con medios físicos de transmisión libres de errores no será necesario. Sin embargo, TCP tiene muchas más características que lo hacen robusto y práctico. TCP puede adaptarse a trabajar en redes con diferentes anchos de banda, topologías, tamaños de paquete, etc. TCP está descrito en los RFC 1122 y 1323 (Request for Comments). La forma básica de trabajo de TCP es que la aplicación le pasa los datos a TCP, éste los toma en unidades menores a 64 Kb (la unidad más usada es 1.5 Kb que es el Maximum Transmission Unit de la mayoría de las tarjetas de red actuales) y se los pasa a IP. IP los toma y los envía (posiblemente por diferentes rutas) a la capa TCP en el destino, el cual los toma y reordena, re-ensambla, pide retransmisiones para aquellas unidades dañadas y entrega los datos a la aplicación destino como si no hubieran pasado por la subred, libres de errores.
8.7.3.1 El modelo de servicio de TCP
El servicio de TCP se ofrece permitiendo que el origen y destino establezcan sus puntos de comunicación llamados sockets, discutidos en la sección 5.3. El socket ya vimos que contiene la dirección del nodo y un número de puerto. El puerto de TCP (por ejemplo el 23 para telnet) es un TSAP (Transport Service Access Point). En un mismo socket se pueden establecer múltiples conexiones, cada conexión es identificada por el par (socket1, socket2). Los puertos cuyo número sea menor a 256 se les llama puertos bien conocidos (well known ports), y son descritos en el RFC 1700.

Todas las conexiones de TCP son full-duplex y punto a punto, TCP no soporta multicasting ni broadcasting. El flujo de datos con TCP es similar a la concepción de lo que es un archivo en UNIX: un flujo de bytes sin ninguna estructura en particular, por esto, si se envían 2 mensajes de 128 bytes, estos pueden llegar al destino como tales o como un solo mensaje de 256 bytes. Existen varias banderas que influyen en cómo trabaja TCP. Por ejemplo, existe la manera de decirle que los datos no sean almacenados en buffers en la capa de transporte, sino que los envíe de inmediato a la aplicación, también hay forma de indicarle que los datos son urgentes. Un segmento de TCP se conforma de un encabezado de 20 bytes. Enseguida pueden ubicarse cero o más palabras de 32 bits de opciones, seguidas de hasta 65 Kb de datos. Si recordamos que el encabezado de IP consume 20 bytes, tenemos un consumo de 40 bytes de control contra 65 Kb de datos, lo cual nos da aproximadamente un 0.06% de sobrecarga de control. Los componentes del encabezado de TCP son como sigue.
Una conexión típica en TCP, donde N1=nodo 1, N2=nodo2, sería:
1. N1_SYN( SEQ=x ) -> N2
2. N2_SYN( SEQ=y, ACK=x+1 ) -> N1,
3. N1_SYN( SEQ=x+1, ACK=y+1 ) -> N2.
Esta plática se conoce como "three way handshake". En el intercambio de mensajes de control para crear y terminar una conexión, TCP puede caer en varios estados.

8.7.3.2 Control de congestión en TCP
La idea básica en el control de congestión es no intentar insertar un nuevo paquete en la red si es que uno anterior no la ha abandonado (se ha entregado). TCP logra la premisa anterior cambiando el tamaño de su ventana. Cuando se inicia una conexión, el emisor manda segmentos de 1K, luego de 2K, luego de 4K y asi sucesivamente esperando una confirmación en cada caso. Cuando la confirmación falla, digamos en 2K, la ventana de congestión se pone de ese tamaño. A este proceso se le llama "comienzo lento". Cada emisor tiene dos ventanas: la de congestión y la que confirma el receptor. Si el receptor dice "envíame segmentos de 4K" pero el emisor ya descubrió que esos segmentos no son confirmados porque rebasan la capacidad de la subred, pone su "ventana confirmada" en 4K y la de congestión en 2K, y finalmente enviará segmentos del tamaño que resulte menor de las dos ventanas, lo cual será la "ventana efectiva". El algoritmo completo contiene otra ventana llamada "holgura" y sirve para afinar el crecimiento exponencial del algoritmo de comienzo lento. La ventana de holgura tiene un tamaño inicial de 64 Kb. cada vez que hay un timeout en el comienzo lento, el valor de la holgura será puesta al valor de la ventana de congestión dividido por dos, y el comienzo lento vuelve a arrancar, excepto que el crecimiento exponencial se detiene cuando se alcanza la holgura. De ahí en adelante la ventana de congestión crece de uno en uno. Por ejemplo, supongamos que una subred puede procesar hasta 12 Kb. Inicialmente la ventana de congestión es 1K, la de confirmación es 0 y la de holgura es 64 K. El emisor inicia el comienzo lento y envía un paquete de 1 K, y el receptor le dice "mándame 24K". El emisor pone la de congestión en 1K, la confirmada en 24K y la holgura en 64K y envía un paquete de 2K. El receptor dice "envíame 24K. El emisor pone la de congestión en 2K y envía un paquete de 4K y obtiene la misma respuesta del receptor. El emisor pone la de congestión en 4K y envía un segmento de 8K, obtiene la misma respuesta y cambia la ventana de congestión a 8K y envía un segmento de 16K, pero como la subred solo soporta 12K, ocurre un timeout y tiene que poner su ventana de holgura a la mitad de la de congestión, es decir, a 4K y reinicia la de congestión a cero. Repite el comienzo lento hasta que su segmento enviado es de 4K, en ese momento su siguiente paquete no será de 8K, sino de 5K, luego de 6,7,8,9,10,11,12,13K donde habrá un timeout y se sabrá que el tamaño de ventana efectiva es de 12K.
8.7.4 Protocolo UDP
El protocolo UDP es simplemente el protocolo IP con un encabezado adicional y es muy útil para aquellas aplicaciones que trabajan en una red de área local donde se supone que la tasa de errores es despreciable, o bien donde la infraestructura de redes mayores (MAN,WAN,etc.) ofrece una capa de red con pocos errores. El protocolo UDP está descrito en el RFC 768. Un paquete de UDP está compuesto de un encabezado de 8 bytes y datos. Los puertos oriígen y destino tienen la misma función que en TCP. El campo de la cadena de chequeo es opcional ya que la calidad de los datos entregados no importa, sólo importa que el paquete en sí sea entregado; por lo tanto se le deja la tarea de chequeo a la aplicación.
8.8 ASPECTOS DEL NIVEL DE APLICACION
Toda la teoría vista hasta ahora es el soporte para crear aplicaciones que funcionan en nuestras LANs, WANs e Internet. Por ejemplo, nuestros programas de sockets son una aplicación muy modesta que puede funcionar tanto en dos nodos de una misma red como situando el cliente en México y el servidor en Australia o viceversa. Revisaremos en esta sección algunos puntos importantes en el uso de aplicaiones de red.
8.8.1 Seguridad de la red
Debido a que cada vez es más común que realicemos nuestras transacciones a través de un medio electrónico en red, necesitamos reforzar la privacía, la protección, la confiabilidad y autenticidad de la información, todo lo cual concierne a la seguridad en red. La seguridad puede reforzarse desde el punto de vista de incluir mecanismos en las diferentes capas del modelo OSI para evitar que la información sea modificada en beneficio del infractor. Los mecanismos pueden ser físicos (seguridad física) o programados. En la capa física es posible que un infractor trate de conectarse al mismo medio físico de transmisión, accesando las señales para su beneficio. En este caso, el uso de fibra óptica entorpecería sus esfuerzos, el uso de cable metálico le permitiría mas facilidades. En la capa de enlace, el protocolo puede conener un algoritmo que encripte los marcos de manera que la capa de enlace del receptor sea el único que puede descifrarlos. Esta misma técnica puede aplicarse en las capas superiores. Como vimos en la sección de firewalls, esta técnica puede ayudarnos a crear túneles o redes virtuales privadas. Se han estudiado y desarrolado una multitud de técnicas de encriptamiento y desciframiento que van más allá del alcance de este curso. La idea es que, tomando una cadena original C, le aplicamos un filtro F() que realiza modificaciones a C produciendo una nueva cadena encriptada F(C) = E. Debe existir un filtro G() que sea capaz de tomar una cadena encriptada y que produzca la cadena original G(E) = C. Los filtros F() y G() pueden auxiliarse de una llave que permita que, aunque el algoritmo G() y F() sean conocidos, sea imposible obtener la cadena C si no se conoce la llave K. Mientras más larga sea la cadena de K, más tiempo de cómputo requiere que un infractor intente adivinarla para descifrar los mensajes.
Los filtros pueden funcionar de varias formas: por susbtitución de subcadenas, por trasposición y por la aplicación de una operación de enmascarado. Los filtros basados en substitución se pueden violar haciendo un análisis de la frecuencia con que ocurren las letras en los diferentes lenguajes, por lo cual no se usan aislados. Los filtros de trasposición también son violables con el mismo principio. Los de enmascarado son seguros, y se puede enviar tanta información como la longitud de la llave. La técnica es sencilla: Al mensaje C aplique un XOR con la llave. En el destino, aplique la llave nuevamente al mensaje cifrado y obtendremos el original. Ahora el problema es cómo compartir la llave. Existen dos principios para usar mensajes cifrados: el primero es que los mensajes deben llevar algunos campos de información redundante que refuercen su significado, de manera que no se puedan confundir con mensajes enviados aleatoriamente. Como esta información redundante puede debilitar el filtro de encriptamiento, se introduce el segundo principio que establece que la información redundante debe ser variable en el tiempo, de manera que evite que el envío de mensajes viejos válidos puedan ser interpretados como correctos y causar problemas. Los mecanismos para crear llaves secretas o para lograr la autentificación más usados comercialmente son DES (Data Encription Standar), RSA (Rivest, Shamir, Adleman), PGP (Pretty Good Privacy), Kerberos, DSS (Digital Signature Standard).
8.8.2 Repaso al DNS
El servicio de nombres DNS es un servicio oculto para los usuarios finales que están acostumbrados a lograr conexiones de Telnet, WWW, FTP, etc. indicando una dirección del tipo "nodo.dominio". Por ejemplo, "telnet imag.imag.fr". Lo que el usuario desconoce, pero que el administrador de red debe instalar, configurar y registrar, es el servicio de nombres.
8.8.2.1 DNS Cliente
Normalmente, la configuración como cliente de DNS es sencilla. Por ejemplo en UNIX se edita un archivo llamado /etc/resolv.conf y se le insertan dos o tres líneas. Por ejemplo, si el servidor de nombres de mi dominio es el nodo 160.32.98.7 y mi dominio es "prueba.gob.mx", el archivo antes mencionado queda como:
domain prueba.gob.mx
nameserver 160.32.98.7
El sistema, al encontrar presente ese archivo al tiempo de iniciación (boot), habilita que los servicios de red resuelvan sus nombres con el servidor indicado.
8.8.2.2 DNS Servidor
La instalación, configuración y registro de un servidor de DNS lleva cuatro pasos:
1. Instalar el software necesario para DNS (BIND) si es necesario
2. Editar los archivos de configuración
· El archivo inicial es /etc/named.boot en UNIX
3. Registrar el dominio en el NIC (Network Information Center) correspondiente
4. Registrar el dominio in-addr.arpa para la resolución inversa en USA.
La mayoría de los sistemas operativos tienen integrado el software para DNS, la edición de los archivos es una tarea ardua.
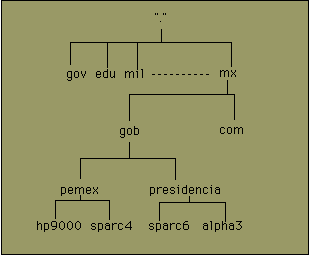
Dominios
Un dominio es una cadena conformada por la concatenación (usando un punto) de los diferentes subdominios partiendo del dominio superior punto. Por ejemplo, existen dominios genéricos y de país. Para México, el dominio superior es "mx". Un subdominio de "mx" es "itesm" o bien "udlap". A su vez, "pue" es un subdominio de "udlap", lo cual nos da el dominio completo "pue.udlap.mx.".
Nombres completamente calificados
Un nombre completamente calificado consiste del nombre del nodo concatenado (con un punto) al dominio completo. Por ejemplo, el nodo "imag" y su dominio completo "imag.fr." nos dan el nombre completamente calificado "imag.imag.fr.". Investigue cuál es el dominio de su red y nombre completamenta algunos nodos. Si tiene aceso a un nodo con UNIX, ejecute ahí el comando "nslookup nodo.dominio" y observe el resultado.
Nombres del dominio inverso o in-addr.arpa
Algunos servicios de Internet necesitan realizar una traducción inversa, es decir, dado una dirección IP se requiere saber su nombre completamente calificado. Para este caso existe el dominio "in-addr.arpa". Un nombre bajo ese dominio tiene un aspecto extraño, por ejemplo, el nodo 192.9.9.7 tiene el nombre "7.9.9.192.in-addr.arpa.". Observe como la dirección IP está al revés. Por ejemplo, algunos servidores de NetNews revisan que los clientes que están conectándose sean realmente un par correcto (nombre calificado, dirección-IP). Lo que hacen es una petición al dominio in-addr.arpa para que, dado su IP, obtengamos su nombre calificado, también denominado como "nombre canónico". Ejecute en un nodo con UNIX los siguientes pasos:
unix> nslookupookup
> set query=ptr
> 1.9.9.192.in-addr.arpa
... salida ...
> quit
unix>
En resumen, el serviciode DNS permite a la comunidad de Internet saber qué IP tiene cada nodo a nivel mundial y logra nombrarlos de manera única. La resolución del nombre es jerárquica y la obligación de cada administrador de red es mantener un servidor primario (tiene las tablas locales de nombres e IPs de los nodos locales únicamente), un servidor secundario (que obtiene copias periódicas del primario) y sus clientes locales.
8.8.3 Repaso al SNMP
Otro servicio ampliamente usado en la comunidad de Internet es el monitoreo de redes fundamentado en el protocolo SNMP (Simple Network management Protocol), descrito en los RFC 1157, 1441-1452). Su funcionalidad es sencilla: En cada nodo de la red se instala un pequeño programa llamado "agente de SNMP" que se encarga, de manera general, de colectar información local del nodo, tal como el número de paquetes de red que se recibieron, el número de paquetes dañados, el número de colisiones, la dirección IP, las tablas locales de enrutado, etc. Este agente, a través del protocolo SNMP, es capaz de comunicarse con un nodo central y enviarle toda esta información o un subconjunto de la misma. Al conjunto completo de información que cada agente soporta se le llama MIB (Management Information Base). El nodo central, denominado Network Operation Center (NOC) puede inspeccionar a intervalos regulares a los agentes de toda una red recolectando la información pertinente para saber es estado actual y generar reportes estadísticos para la toma de decisiones. Las MIB están especificadas en un lenguaje estándard llamado Abstract Sintax Notation One que tiene cuatro tipos de datos primitivos: Entero, cadena de bits, Octeto, Nulo e Identificador de objeto. El protocolo en sí soporta un conjunto de operaciones muy sencillas que son: Get-request (obtiene el valor de una variable MIB), Get-next-request (obtiene la siguiente variable MIB), Get-bulk-request (obtiene toda una tabla de variables MIB), Set-request (le dice al agente que modifique el valor de una variable MIB), Inform-request (dsecripción de la MIB local) y SnmpV2-trap (reporte de un agente hacia el NOC).

©
GRUPO REDMEX, DIRIGIDO POR ARTURO ROTA
COLABORACIONES DE
Claudia Vasconcelos, Isidro del Arco, Carolina Duarte, Armando Esquivel, Enrique Sacristán, Luis Sánchez-Mesa, Roberto Gómez, Antonio Segarra y Javier de Lucas